
- home of git’s git repo: https://git-scm.com/
-
# to clone git's git repo git clone https://git.kernel.org/pub/scm/git/git.git # as can be seen there, it is STILL under active development
-
- written in primarily in C, with GUI and programming scripts written in Shell script, Perl, Tcl and Python[4][5]
- one of it’s credos is: “distributed-even-if-your-workflow-isnt“
- git was initially written by Linus Torvalds on the idea: how to create source code management system that does not suck
- well was pretty happy with svn, but of course Mr Torvalds manages a software project (the GNU Linux kernel) with THOUSANDS of developers and MILLIONS of commits a day, so there was the plausible wish for something that was specific to that task, if it works for others, that might be a nice sideffect.
- currently maintained by Junio C Hamano. Numerous contributions have come from the Git mailing list git ÄT vger DOT kernel DOT org. openhub.net/p/git/contributors/summary
-
just btw: “Black Duck Open Hub, formerly Ohloh,[2] is a website which provides a web services suite and online community platform that aims to index the open-source software development community. It was founded by former M$ managers Jason Allen and Scott Collison in 2004 and joined by the developer Robin Luckey” (src)
- have a clone of git.git itself, the output of git-shortlog(1) and git-blame(1) can show you the authors for specific parts of the project.
-
- source code management is very useful when the developer team is x > 1 developer.
- it allows fast syncing of projects (e.g. from work-desktop to home-laptop and vice versa)
- It seems to be a very holistic/complete/robust design and implemented file-based (no mysql server needed) source control system,
- that has some complexity to it. Complexity might be reduced by using scripts or tools (vscode, eclipse) to simplify the tasks.
- with all complex systems: usually only those devs that wrote it TRULY understand why-what-is-going-on-right-or-wrong-under-the-hood
- git is not only good for source code management
- some even use it as content management system (version control of documents and other files (anything where organized cooperation between multiple users/developers/designers/content creators is important)).
- GitHub is not run by Linux Foundation or Linus, it is basically not more than “web frontend” for a centralized source code on a not-owned-by-the-user-server system, sold for $7.5 billions to M$
- it is great for sharing open source src software
- but setting up the user-soon-dev’s own ssh vm (virtual machine also refered to as vps or “cloud”) debian 12 based server is fast and not-so-expensive: model: CAX11, vCPU 2x Ampere ARM + RAM 4 GB + Disk space 40 GB + Traffic 20 TB + IPv4 ~ 4.50 per month (2024-03)
- but it is possible to setup a self-hosted gitlab (nice web gui)
- git-server-side-storage-style: when trying to find the files pushed to the git-repo-server, by their filename, the user will probably not get lucky because…

just because Torvalds likes it does not mean it’s the right thing for everyone and everything
the good about git over ssh:
- + free + open source
- + relatively fast and easy setup (scroll down): requirements: a working secure open ssh server
- + well thought out concept (time will tell)
- + high quality (almost-error-free) software (time will show)
- + well documented INCLUDING video tutorials (QUALITY UNTESTED)
- ~ various gui front ends SHOULD (if they themselves don’t get too complicated) make interaction with git repos easier but well
-
- + one written in perl even hosted where the git src are hosted on kernel.org (the Linus approved gui?)
- https://git-scm.com/docs/gitk
- install like:
-
su - root -
apt update; apt install git gitk git-gui; # start it like git gui
- look like this:
-
- there is more to be found here: “Cogito (originally git-pasky) is a revision control system layered on top of Git. It is historically the first Git frontend, which appeared in April 2005″ (src)
the problem with git over ssh:
- – renaming-the-wheel: why rename something that already has a name? a commit is basically just an “upload” of changes of code, so call it an “upload” (it’s too late now)
- imho this is a mistake done often by various commercial companies for marketing purposes: coming up with “buzzwords” for things that already exist and have a name = causes inefficiencies = new devs have to find out that “what is what” and that a “commit” is just a “upload” of changes of code
- – overhead of having to learn another complex software, this complexity can get in the way of actually coding
- – if all devs push in one branch (which they should not do) it might be hard to revert changes, which is one of the most basic and fundamental functions of a code management system
- – if passwordless public-private-ssh-key auth shall be used to commit changes, the private key of this user needs to be on every system that wants to clone a
repo, so if the private key get’s in the wrong hands, the whole git-ssh-server is in danger of becoming ranomeware-deleted- — the result is: brute-forcable password auth is enabled, except to be brute-foced night-and-day
- eclipse egit offers to save the password in a more-or-less secure way (expect it to be less secure)
- — the result is: brute-forcable password auth is enabled, except to be brute-foced night-and-day
- – it happened more than once, that devs git-commit-uploaded sensitive information as access tokens, passwords and more-or-less private mail addresses to github
- – so while it is possible to set a filter file .gitignore to ignore certain files and folders it is often forgotten and then security problems can happen 🙁 (especially on repos that are publicly visible, not so much on the dev’s own ssh server… there bruteforce password attacks are the bigger threat)
be aware! git is a complex system!
only god & nobody is perfect thus complexity means: errors & problems and this means: frustrations
if the admin-dev-user does not plan to use it on a daily basis, it might not be worth diving down on it and maybe (for small teams might be okay) use (S)FTP? (also very easy to setup)
there definately need to be more tools to simplify the usage of git (pull, merge, push)
git-over-ssh is a cool combination
- every GNU Linux / OSX and even Windows (putty) can do ssh
- ssh enables secure encrypted transfer of the files
- ssh server is very easy to setup and with strong passwords also very secure (filtering of brute force traffic should non the less be done as well, bash savy admins can look here for inspiration)
- does DELTA transfer meaning: small changes to big files can be transferred/synced fast (faster internet/more bandwidth is always a plus) (so in theory even large movie.mp4 and sound.wav files should be possible)
given that the requirements:
- make sure password (or more convenient public-private key auth) ssh login from client->server works
- it seems that as little as 256MByte of (VM asigned) RAM is sufficient
free -m; # superbly efficient
total used free shared buff/cache available
Mem: 231 65 30 2 135 154
Swap: 1020 0 1020
are already in place (https://dwaves.de/2017/05/05/linux-ssh-generate-public-private-keys/)
one can setup one’s own git repository in 10min:
# tested on hostnamectl; # client Static hostname: client Icon name: computer-desktop Chassis: desktop Operating System: Debian GNU/Linux 10 (buster) Kernel: Linux 4.19.0-8-amd64 Architecture: x86-64 hostnamectl; # server Static hostname: git Icon name: computer-vm Chassis: vm Operating System: Debian GNU/Linux 10 (buster) Kernel: Linux 4.19.0-8-amd64 Architecture: x86-64 # DEFINATELY enable ssh logging (not enabled per default on Debian) # for conveniance an ll alias is recommended # create ll alias to nicely display folder contents alias ll='ls -lah --color --time-style=+%F' # add this line to /etc/bashrc or /etc/bash.bashrc # ===== on (ssh-enabled)server ===== # create repository directory (where to store project on server) mkdir -p ~/projects/test cd ~/projects/test # initialize the server folder as git repository git init --bare # ===== on client ===== # create repository directory (where to store project on client) mkdir -p ~/projects/test cd ~/projects/test # initialize the client folder as git repository git init # create some test data echo -e "this is a test git repository created on $(date '+%Y-%m-%d-%H:%M:%S')" > README.txt; # make git realize there are new files git add . # the git-system will not proceed, stating it needs to know more about the user # okay let's give X-D # this identifies all changes-commits by username@hostname # (usefull in teams to track: what user from what machine did those changes) git config --global user.name "user" git config --global user.email "user@$(hostname)" # create a commit git commit -m "the_very_beginning" -a # connect the server git repository to client # if 1234 is git-server-ssh-port (change) git remote add origin ssh://user@server.com:1234/home/user/projects/test # or if "target" is on the same system as development (everything local) add "local" origin like git remote add origin /home/user/projects/test # optional: error-correction: if the origin needs to be modified # it first needs to be deleted, then re-added git remote remove origin # on client: push/sync local changes to server git push origin master # then try again git remote add origin ssh://user@server.com:1234/home/user/projects/test git push origin master ### HURRAY! :) ONE JUST CREATED A NEW GIT REPO! # AND SYNCED CHANGES TO IT! :) # CONGRATULATIONS ALL INVOLVED!# now let's see if one can pull the changes # (maybe on a different 3rd (virtual)machine?) # (anything but localhost works) cd ~/projects/ # pull repo to local folder (folder test will be automatically created) git clone ssh://user@server.com:1234/home/user/projects/test Cloning into 'test'... remote: Enumerating objects: 3, done. remote: Counting objects: 100% (3/3), done. remote: Compressing objects: 100% (2/2), done. remote: Total 3 (delta 0), reused 0 (delta 0) Receiving objects: 100% (3/3), done. # let's see what one got ll total 28K drwxr-xr-x 3 user user 4.0K Apr 25 13:29 . drwxr-xr-x 357 user user 20K Apr 25 13:27 .. drwxr-xr-x 3 user user 4.0K Apr 25 13:29 test ll test total 16K drwxr-xr-x 3 user user 4.0K 2020-04-25 . drwxr-xr-x 3 user user 4.0K 2020-04-25 .. drwxr-xr-x 8 user user 4.0K 2020-04-25 .git -rw-r--r-- 1 user user 52 2020-04-25 README.txt cat ./test/README.txt this is a test git repository created on 2020-04-25 ### HURRAY! one just successfully pulled the project from server to client :) # view status of this git repo (what branch) git log # to change the location on server or the server git remote remove origin git remote add origin ssh://user@newserver.com:12345/new/location
how to clone the repo?
“cloning” aka downloading the files inside the repo to the local machine works like this:
git clone ssh://user@server.com:1234/home/user/projects/test
how to update local?
before changing files!
always pull the latest changes from git-srv! 🙂
this can easily be forgotten…
clone yesterday… work-make-changes today… argh… local files not up to date and might need merging
in order to refresh the local files with the latest changes from git-srv cd into the project folder then:
git pull origin master
PS: git pull origin master does NOT delete newly created local files
let’s script it:
its always more convenient, to just run /scripts/do_stuff.sh ProjectName
than to actually go through each and every necessary command
NOTE!
instead of ~/projects one has (unwisely) chosen /projects (subfolder of root) (please modify X-D)
server:
create new project script
vim /scripts/git.server.add_project.sh #!/bin/bash echo "===== create new dir for project =====" mkdir -p ~/projects/$1 echo "===== change into that dir =====" cd ~/projects/$1 echo "===== git init --bare =====" git init --bare
client:
note: my project folder is /projects not /home/user/projects (which might be an better idea depending on how one runs backups)
git.client.add_project.sh
the idea is to create an empty local folder and git repo (which this script generates)
add folders
commit them (commit itself does not upload the files, git push does)
need to be changed: ip and username and port of ssh-git-server
cat /scripts/git.client.add_project.sh #!/bin/bash echo "=== create repository directory (where to store project on client) ===" mkdir -p /projects/$1 cd /projects/$1 echo "=== remove exisint maybe old .git dir if present ===" rm -rf .git echo "=== initialize the client folder as git repository ===" git init echo "=== make git realize there are new files ===" git add . echo -e "this repository was created $(date '+%Y-%m-%d-%H:%M:%S')\n\r and this file is the first/initial commit" > README.txt echo "=== create a commit ===" git commit -m "first-initial commit, added README.txt" -a echo "=== connect the server git repository to client ===" # 2223 is the port ssh is running on git remote add origin ssh://$USER@123.ip.of.server:port1234/home/$USER/projects/$1 echo "=== push/sync local changes to server ===" git push origin master
download = clone a repository server2local:
to download a repo from server2local is called to clone
if ther user pulls a repo it is not cloned (no files visible)
cat /scripts/git.download.project.sh #!/bin/bash echo "=== create repository directory (where to store project on client) ===" mkdir -p /projects/$1 cd /projects/$1 echo "=== remove exisint maybe old .git dir if present ===" rm -rf .git echo "=== initialize the client folder as git repository ===" git init echo "=== make git realize there are new files ===" git add . echo -e "this repository was created $(date '+%Y-%m-%d-%H:%M:%S')\n\r and this file is the first/initial commit" > README.txt echo "=== connect the server git repository to client ===" # port1234 is the port ssh is running on git remote add origin ssh://$USER@123.ip.of.server:port1234/home/$USER/projects/$1 echo "=== push/sync local changes to server ===" git clone ssh://$USER@123.ip.of.server:port1234/home/$USER/projects/$1
upload/commit changes to server script:
this script is meant that when changes were made to the empty local repo
to upload = commit them
before changes can be uploaded “commited”
it is required to identify the user
in order to track, what user made what changes
# set per-project identity info git config --global user.email "user@domain.com" git config --global user.name "user"
cat /scripts/git.client.commit.sh #!/bin/bash echo "=== sync changes from client to master git repo@server ===" echo "= project: $1 =" echo "= changing directory =" cd $1 echo "= adding files =" git add . echo "= committing changes =" git commit -m "$2" echo "= uploading changes =" git push origin master
# usage
/scripts/git.client.commit.sh local_project_folder "commit message"
git digital workflow in a nice chart:
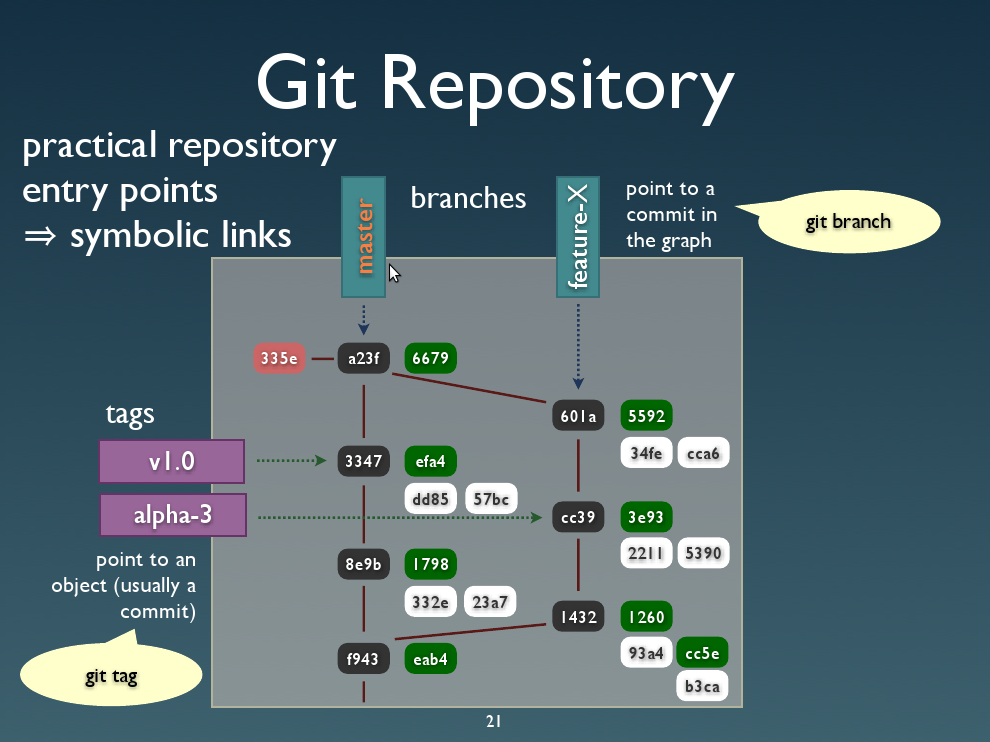
tips + hints:
if the initial files files for the repo are on a a server and the local empty folder shall become a git repo, the user might encouter this error
- git.error: “There is no tracking information for the current branch. Please specify which branch you want to merge with. See git-pull(1) for details.”
simply instead of
git pull # try git pull origin master # if this fails try git branch --set-upstream-to=origin/master master git pull
- git.error: “error: src refspec main does not match any”
this means there is no such branch in the server’s repository
if the user tried: git push origin main
try it with: git push origin master
(unfortunately, there does not seem to be a default branch name definition? with github using “main”)
common (everyday) git problems and pitfalls:
- during git add . “fatal: detected dubious ownership in repository at”
- “happens when a repo was cloned by a different user than your current user” (src)
- but git also delivers a possible workaround in the error message:
- To add an exception for this directory, call:
git config --global --add safe.directory ~/projects/name-of-git-project-folder
automating updates
before the ide (for example PyDev eclipse) starts, it would be nice to pull the latest changes e.g. work with the latest version of the repo, this is okay for small teams with low probability of merge conflicts (two devs touching the same file at the same time)
this is super conveniant, because it pulls the latest changes and starts eclipse
put this on startup:

# script1, used to start script2 vim /scripts/start.mate-termina.sh #!/bin/bash # update repos with latest changes on start mate-terminal -e "/scripts/start.sh" # script2 vim /scripts/start.sh #!/bin/bash # update repos with latest changes on start echo "... updating repos" # default pydev-eclipse workspace for git repos is ~/git base_directory="/home/user/git" # Iterate over each directory find "$base_directory" -maxdepth 1 -not -path ".metadata" -not -path "git" -not -path ".git" -type d | while read -r dir; do echo "...pulling latest changes of project: $dir" git config --global --add safe.directory $dir cd $dir; git pull; done echo "... starting eclipse" /home/user/eclipse/eclipse/eclipse # also of course don't forget to chmod +x /scripts/*.sh
PS:
man git: git.man.txt “git – the stupid content tracker”
Links:
https://www.linux.com/training-tutorials/how-run-your-own-git-server/
https://dwaves.de/2016/10/01/github-com-cheat-sheed/
PS: as with all complex systems/tools, if not used on a daily basis, the usage could be forgotten and needs to be relearned.
but maybe one does not need ALL of it’s features from day one 😉
liked this article?
- only together we can create a truly free world
- plz support dwaves to keep it up & running!
- (yes the info on the internet is (mostly) free but beer is still not free (still have to work on that))
- really really hate advertisement
- contribute: whenever a solution was found, blog about it for others to find!
- talk about, recommend & link to this blog and articles
- thanks to all who contribute!
