“XFS is a high performance journaling filesystem which originated on the SGI IRIX platform.”
SGI (Silicon Graphics) is out of business since 2009.
“The addition of 3D graphic capabilities to PCs, and the ability of clusters of Linux– and BSD-based PCs to take on many of the tasks of larger SGI servers, ate into SGI’s core markets. The porting of Maya to Linux, Mac OS X and Microsoft Windows further eroded the low end of SGI’s product line.” (Wikipedia)
So SGI “Silicon Graphics Inc.” – as the name says – was all about 3D rendering and digital animations and machines specifically build for this purpose.
20 years ago (ask me) computers were pretty bad at 3D animations.
I remember i had to buy a separate arithmetic CPU for the Atari Falcon 030 to make it run Neon 3D which was a 300 DM expensive 3D rendering program that could not handle more than 1000 polygons and took like 15 minutes to render a single frame/picture.
What remains of all of this…

SGI Altix 4700 systems datacenter Bayern II AltiX https://www.lrz.de/wir/einweihungsfeier/bildergalerie/_fotoindex.html

altix sgi origin onyx 3000 cpu s-l300
Is their filesystem…. 😀
It is completely multi-threaded, can support large files and large filesystems, extended attributes,
variable block sizes, is extent based, and makes extensive use of Btrees (directories, extents, free space) to aid both performance and scalability.” (src: apt-cache show xfsprogs)
I believe filesystems come with different concepts – maturity – features – and it is almost like with the distributions – you basically need to know – what you need in order to make the right choice.
Due to it’s larger write-RAM-cache it performs definately faster than ext3 but that means – possible partition and dataloss – especially if system loses power and does not shutdown properly.
DO NOT USE XFS WITHOUT A PROPERLY CONFIGURED UPS!
A reader that commented on this article – made very bad experiences with XFS: „UPS, battery-backed data caching, none of it matters. If you run XFS, it will burn you sooner or later. I have had 4 XFS systems in the last 2 years, every…single…one of them has failed.“
Interesting that SUSE12 server is using XFS for /home. They seem to completely trust it.
If you don’t need this or that feature and you just want a rock solid filesystem – it is probably best just to stick to ext3 until 2020 and then go to ext4 😀 (let it ripe for like 20 years 😀 just for your data to be save – no experiments here! – i guess you don’t have a backup of your backup – do you?)
ext3 can do maximal filesize of individual files of 4TByte which should be okay for most users – even when using virtual machines (in VirtualBox
If you do not have need to manage petabytes-size-partitions ext3 and ext4 are just about all you will need.
“ext2/3/4 have terrible large-directory performance. If you create 100,000 files in a directory in an ext2/3/4 filesystem, enumerating said files (ls, readdir, etc.) becomes unbearably slow — and the slowness persists even after you delete all but one of the files in the directory.” (src)
You can actually test that with this python based benchmark that creates 300.000 files in one folder.
NOTE: These results may not apply to on-bare-metal installations – this is a Hyper-V Debian8.8
(kernel: Linux debian 3.16.0-4-686-pae #1 SMP Debian 3.16.43-2 (2017-04-30) i686 GNU/Linux)
VM (harddisk speed of host is limiting factor – always goes up to 100% during these test – but some RAM caching might be going on):
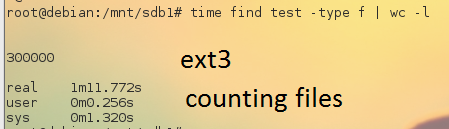
took 1minute and 11 seconds to count the 300.000 files in this directory with find and wc
a second run was 35seconds, a 3rd run 0.5 seconds sooo yeah RAM caching 😀

list files and save to file was faster… 3 seconds
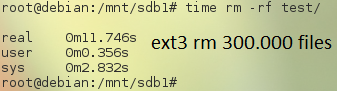
removing took 11 seconds… is okay i think 😉
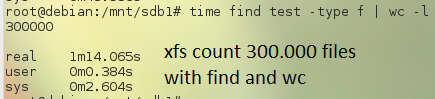
rerun finished in 0.3 seconds
… so atleast in this virtual environment i can’t confirm that xfs is faster than ext3 when dealing with a lot of files in one directory.
but maybe i am missing something here.
Missing undelete – saved my ass more than once – is another reason NOT to use XFS. (sorry)
Q: Does the filesystem have an undelete capability?
There is no undelete in XFS.
However, if an inode is unlinked but neither it nor its associated data blocks get immediately re-used and overwritten, there is some small chance to recover the file from the disk.
photorec, xfs_irecover or xfsr are some tools which attempt to do this, with varying success.
There are also commercial data recovery services and closed source software like Raise Data Recovery for XFS which claims to recover data, although this has not been tested by the XFS developers.
As always, the best advice is to keep good backups.
src: http://xfs.org/index.php/XFS_FAQ#Q:_Does_the_filesystem_have_an_undelete_capability.3F
http://linuxwebdev.blogspot.de/2005/06/xfs-undelete-howto-how-to-undelete.html
> Tested by time (I’m the OP).
This is so important, and so often overlooked.
The lure of “ohhh shiny!” is prevalent in tech. I love to use bleeding edge stuff, play with new toys etc, but that is purely for home and personal stuff. Never for work.
I want my work life to be utterly boring. Nothing breaking. Everything behaving exactly as expected. I will happily trade a bit of performance and a lack of some shiny features for a system or component that works reliably. The less time I have to spend fighting stuff the more time I can spend tuning, automating or improving what I do have to look after.
XFS performs well. It’s reliable, reasonably fast (they trade some speed for durability/reliability), and just works
XFS: A high-performance journaling filesystem
XFS combines advanced journaling technology with full 64-bit addressing and scalable structures and algorithms. This combination delivers the most scalable high-performance filesystem ever conceived.
Current XFS community activity: XFS.org Wiki
Questions and Problems
If you have any questions or problems with the installation or administration of XFS, you can send email to xfs@oss.sgi.com. Note that this address is a public mailing list; please search the list archive to see if your question has been answered previously.
To report any bugs you encounter in XFS, use the SGI Bugzilla database.
Features
The XFS filesystem provides the following major features:
- Quick Recovery The XFS journaling technology allows it to restart very quickly after an unexpected interruption, regardless of the number of files it is managing. Traditional filesystems must do special filesystem checks after an interruption, which can take many hours to complete. The XFS journaling avoids these lengthy filesystem checks.
- Fast TransactionsThe XFS filesystem provides the advantages of journaling while minimizing the performance impact of journaling on read and write data transactions. Its journaling structures and algorithms are tuned to log the transactions rapidly.XFS uses efficient tree structures for fast searches and rapid space allocation. XFS continues to deliver rapid response times, even for directories with tens of thousands of entries.
- Massive ScalabilityXFS is a full 64-bit filesystem, and thus is capable of handling filesystems as large as a million terabytes.
263 = 9 x 1018 = 9 exabytes
A million terabytes is thousands of times larger than most large filesystems in use today. This may seem to be an extremely large address space, but it is needed to plan for the exponential disk density improvements observed in the storage industry in recent years. As disk capacity grows, not only does the address space need to be sufficiently large, but the structures and algorithms need to scale. XFS is ready today with the technologies needed for this scalability.
XFS also continues to evolve to match the capabilities of the hardware it is being deployed on. Efficiency when dealing with large amounts (terabytes) of main memory and hence large numbers of active files and large amounts of cached file data are areas demanding continual improvements. Extending XFS to improve performance on large NUMA machines is also an area of active research and development.
- Efficient AllocationsXFS implements extremely sophisticated space management techniques. Efficiency in space management has been achieved through the use of variable sized extents, rather than the simple single-block-at-a-time mechanism of many other filesystems. XFS was the first filesystem to implement delayed space allocation for buffered writes, supports direct I/O, provides an optional realtime allocator, and is able to align allocations based on the geometry of the underlying storage device. The XFS allocator performs admirably in the presence of multiple parallel writers, and is renowned for its resistance to space fragmentation under such conditions.
- Excellent BandwidthXFS is capable of delivering very close to the raw I/O performance that the underlying hardware can provide. XFS has proven scalability on SGI Altix systems of multiple gigabytes-per-second on multiple terabyte filesystems.
Technical Specifications
Technology
Journaled 64-bit filesystem with guaranteed filesystem consistency.
Availability
XFS is available for Linux 2.4 and later Linux kernels.
Online Administration
XFS supports filesystem growth for mounted volumes, allows filesystem “freeze” and “thaw” operations to support volume level snapshots, and provides an online file defragmentation utility.
Quotas
XFS supports user and group quotas. XFS considers quota information as filesystem metadata and uses journaling to avoid the need for lengthy quota consistency checks after a crash. Project quota are now also supported, and these can be used to provide a form of directory tree quota.
Extended Attributes
XFS implements fully journaled extended attributes. An extended attribute is a name/value pair associated with a file. Attributes can be attached to all types of inodes: regular files, directories, symbolic links, device nodes, and so forth. Attribute values can contain up to 64KB of arbitrary binary data. XFS implements three attribute namespaces: a user namespace available to all users, protected by the normal file permissions; a system namespace, accessible only to privileged users; and a security namespace, used by security modules (SELinux). The system namespace can be used for protected filesystem meta-data such as access control lists (ACLs) and hierarchical storage manager (HSM) file migration status.
POSIX Access Control Lists (ACLs)
XFS supports the ACL semantics and interfaces described in the draft POSIX 1003.1e standard.
Maximum File Size
For Linux 2.4, the maximum accessible file offset is 16TB on 4K page size and 64TB on 16K page size. For Linux 2.6, when using 64 bit addressing in the block devices layer (CONFIG_LBD), file size limit increases to 9 million terabytes (or the device limits).
Maximum Filesystem Size
For Linux 2.4, 2 TB. For Linux 2.6 and beyond, when using 64 bit addressing in the block devices layer (CONFIG_LBD) and a 64 bit platform, filesystem size limit increases to 9 million terabytes (or the device limits). For these later kernels on 32 bit platforms, 16TB is the current limit even with 64 bit addressing enabled in the block layer.
Filesystem Block Size
The minimum filesystem block size is 512 bytes. The maximum filesystem block size is the page size of the kernel, which is 4K on x86 architecture and is set as a kernel compile option on the IA64 architecture (up to 64 kilobyte pages). So, XFS supports filesystem block sizes up to 64 kilobytes (from 512 bytes, in powers of 2), when the kernel page size allows it.
Filesystem extents (contiguous data) are configurable at file creation time using xfsctl(3) and are multiples of the filesystem block size. Individual extents can be up to 4 GB in size.
Physical Disk Sector Sizes Supported
512 bytes through to 32 kilobytes (in powers of 2), with the caveat that the sector size must be less than or equal to the filesystem blocksize.
NFS Compatibility
With NFS version 3, 64-bit filesystems can be exported to other systems that support the NFS V3 protocol. Systems that use NFS V2 protocol may access XFS filesystems within the 32-bit limit imposed by the protocol.
Windows Compatibility
SGI uses the Open Source Samba server to export XFS filesystems to Microsoft Windows systems. Samba speaks the SMB (Server Message Block) and CIFS (Common Internet File System) protocols.
Backup/Restore
xfsdump and xfsrestore can be used for backup and restore of XFS file systems to local/remote SCSI tapes or files. It supports dumping of extended attributes and quota information. As the xfsdump format has been preserved and is now endian neutral, dumps created on one platform can be restored onto an XFS filesystem on another (different architectures, and even different operating systems – IRIX to Linux, and vice-versa).
Support for Hierarchical Storage
The Data Management API (DMAPI/XDSM) allows implementation of hierarchical storage management software with no kernel modifications as well as high-performance dump programs without requiring “raw” access to the disk and knowledge of filesystem structures.
Optional Realtime Allocator
XFS supports the notion of a “realtime subvolume” – a separate area of disk space where only file data is stored. Space on this subvolume is managed using the realtime allocator (as opposed to the default, B+ tree space allocator). The realtime subvolume is designed to provide very deterministic data rates suitable for media streaming applications.
src: http://oss.sgi.com/projects/xfs/
now the testdrive
home some test-harddisk or partition ready…
hostnamectl; # tested on Static hostname: debian9 Icon name: computer-vm Operating System: Debian GNU/Linux 9 (stretch) Kernel: Linux 4.12.0cuztom Architecture: x86-64 su; # become root apt-get update; apt-get install xfsprogs; # install xfs kernel modules and utilities mkfs.xfs -V; # you should now have a xfs capable system mkfs.xfs version 4.9.0 fdisk /dev/sdb; # add a new partition mkfs.xfs -L LABEL /dev/sdb1; # format with xfs mkfs.xfs -f -L LABEL /dev/sdb1; # format with xfs if it was already meta-data=/dev/sdb1 isize=512 agcount=4, agsize=655360 blks = sectsz=4096 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0 data = bsize=4096 blocks=2621440, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=4096 sunit=1 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 lsblk -fs|grep xfs sdb1 xfs LABEL 4333454d-9dc5-475c-be35-96e585558753 mkdir /mnt/xfs1; # make mountpoint mount /dev/sdb1 /mnt/xfs1; xfs_info /mnt/xfs1/ meta-data=/dev/sdb1 isize=512 agcount=4, agsize=655360 blks = sectsz=4096 attr=2, projid32bit=1 = crc=1 finobt=1 spinodes=0 rmapbt=0 = reflink=0 data = bsize=4096 blocks=2621440, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal bsize=4096 blocks=2560, version=2 = sectsz=4096 sunit=1 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 umount /mnt/xfs1/; # in order to do filesystem check xfs_repair /dev/sdb1 Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... done
backup and restore
xfsdump and xfsrestore allows incremental backups.
the backup source is specified as mounted xfs folder!
the destination is a (can be unformatted) block device! (not a mounted folder)
dmesg|grep -i xfs [ 135.044300] SGI XFS with ACLs, security attributes, realtime, no debug enabled apt-get install xfsdump; # install additional utility to backup xfs filesystems mount /dev/sdb1 /mnt/xfs1 echo "this is a test file" > /mnt/xfs1/test.txt; # create some test data to backup lsblk|grep sdb9; # unformatted partition where backup will be stored (destination) └─sdb9 8:25 0 10G 0 part root@debian9:/mnt# lsblk|grep sdb1 ├─sdb1 8:17 0 10G 0 part /mnt/xfs1; # this will be backuped live! xfsdump -l 0 -f /dev/sdb9 /mnt/xfs1 xfsdump: using file dump (drive_simple) strategy xfsdump: version 3.1.6 (dump format 3.0) - type ^C for status and control ============================= dump label dialog ============================== please enter label for this dump session (timeout in 300 sec) -> FULL session label entered: "FULL" --------------------------------- end dialog --------------------------------- xfsdump: level 0 dump of debian9:/mnt/xfs1 xfsdump: dump date: Mon Jul 10 11:55:38 2017 xfsdump: session id: 984759b4-2af5-4329-bec8-6fb60d810480 xfsdump: session label: "FULL" xfsdump: ino map phase 1: constructing initial dump list xfsdump: ino map phase 2: skipping (no pruning necessary) xfsdump: ino map phase 3: skipping (only one dump stream) xfsdump: ino map construction complete xfsdump: estimated dump size: 21760 bytes ============================= media label dialog ============================= please enter label for media in drive 0 (timeout in 300 sec) -> xfs_backup_partition media label entered: "xfs_backup_partition" --------------------------------- end dialog --------------------------------- xfsdump: creating dump session media file 0 (media 0, file 0) xfsdump: dumping ino map xfsdump: dumping directories xfsdump: dumping non-directory files xfsdump: ending media file xfsdump: media file size 21952 bytes xfsdump: dump size (non-dir files) : 0 bytes xfsdump: dump complete: 9 seconds elapsed xfsdump: Dump Summary: xfsdump: stream 0 /dev/sdb9 OK (success) xfsdump: Dump Status: SUCCESS ll /mnt/xfs1/; # test data is there total 8.0K drwxr-xr-x 2 root root 22 Jul 10 12:06 . drwxr-xr-x 14 root root 4.0K Jul 10 2017 .. -rw-r--r-- 1 root root 20 Jul 10 12:05 test.txt rm -rf /mnt/xfs1/*; # now let's delete the test data xfsrestore -I file system 0: fs id: 4333454d-9dc5-475c-be35-96e585558753 session 0: mount point: debian9:/mnt/xfs1 device: debian9:/dev/sdb1 time: Mon Jul 10 11:52:11 2017 session label: "FULL" session id: 4aeb1e7c-167a-4898-b026-f03858a065d1 level: 0 resumed: NO subtree: NO streams: 1 stream 0: pathname: /dev/sdb9 start: ino 99 offset 0 end: ino 102 offset 0 interrupted: NO media files: 1 media file 0: mfile index: 0 mfile type: data mfile size: 21952 mfile start: ino 99 offset 0 mfile end: ino 102 offset 0 media label: "xfs_backup" media id: ebe11539-024d-4521-b109-b2e6d68763cc session 1: mount point: debian9:/mnt/xfs1 device: debian9:/dev/sdb1 time: Mon Jul 10 11:55:38 2017 session label: "FULL" session id: 984759b4-2af5-4329-bec8-6fb60d810480 level: 0 resumed: NO subtree: NO streams: 1 stream 0: pathname: /dev/sdb9 start: ino 99 offset 0 end: ino 102 offset 0 interrupted: NO media files: 1 media file 0: mfile index: 0 mfile type: data mfile size: 21952 mfile start: ino 99 offset 0 mfile end: ino 102 offset 0 media label: "xfs_backup_partition" media id: 50667c15-cb22-4722-b864-28cdb0795cda xfsrestore: Restore Status: SUCCESS xfsrestore -f /dev/sdb9 -S 984759b4-2af5-4329-bec8-6fb60d810480 /mnt/xfs1 xfsrestore: using file dump (drive_simple) strategy xfsrestore: version 3.1.6 (dump format 3.0) - type ^C for status and control xfsrestore: using online session inventory xfsrestore: searching media for directory dump xfsrestore: examining media file 0 xfsrestore: reading directories xfsrestore: 1 directories and 3 entries processed xfsrestore: directory post-processing xfsrestore: restoring non-directory files xfsrestore: restore complete: 0 seconds elapsed xfsrestore: Restore Summary: xfsrestore: stream 0 /dev/sdb9 OK (success) xfsrestore: Restore Status: SUCCESS cat /mnt/xfs1/test.txt; # the file has been restored this is a test file
i guess it’s best to do your own experiments with it… and see if it works for you.
incremental backups – nice – but no export to file?
acronis and other backup software can incrementally snapshot/export/backup/save and restore live filesystems to and from a file.
(they operate like vss – halting the live filesystem – redirecting write actions somewhere else – while the snapshot/backup/export is running)
while there seems to be no direct export to file with xfsdump.
you can do a backup of the backup.
you can backup the xfsdump-to-raw-partition (tape-drive-style) backup with dd: (not incremental though :-D)
# fill the filesystem with some test data from /usr cp -rv /usr /mnt/xfs1/ df -Th|grep xfs1 /dev/sdb1 xfs 10G 1.1G 9.0G 11% /mnt/xfs1 # backup more data = takes longer xfsdump -l 0 -L "Backup level 0 of /mnt/xfs1 `date`" -f /dev/sdb9 /mnt/xfs1 xfsdump: using file dump (drive_simple) strategy xfsdump: version 3.1.6 (dump format 3.0) - type ^C for status and control xfsdump: level 0 dump of debian9:/mnt/xfs1 xfsdump: dump date: Tue Jul 11 16:12:08 2017 xfsdump: session id: ae33309e-75f3-465a-b894-a4e4a63868e7 xfsdump: session label: "Backup level 0 of /mnt/xfs1 Tue Jul 11 16:12:08 CEST 2017" xfsdump: ino map phase 1: constructing initial dump list xfsdump: ino map phase 2: skipping (no pruning necessary) xfsdump: ino map phase 3: skipping (only one dump stream) xfsdump: ino map construction complete xfsdump: estimated dump size: 1051017728 bytes ============================= media label dialog ============================= please enter label for media in drive 0 (timeout in 300 sec) -> more data media label entered: "more data" --------------------------------- end dialog --------------------------------- xfsdump: creating dump session media file 0 (media 0, file 0) xfsdump: dumping ino map xfsdump: dumping directories xfsdump: dumping non-directory files xfsdump: ending media file xfsdump: media file size 995474848 bytes xfsdump: dump size (non-dir files) : 984774880 bytes xfsdump: dump complete: 70 seconds elapsed xfsdump: Dump Summary: xfsdump: stream 0 /dev/sdb9 OK (success) xfsdump: Dump Status: SUCCESS dd if=/dev/sdb9 | pv | gzip -c > /mnt/ext3/sdb9_backup_of_backup_of_xfs1.img 10GiB 0:02:17 [74.5MiB/s] [ <=> ] 20971520+0 records in 20971520+0 records out 10737418240 bytes (11 GB, 10 GiB) copied, 137.343 s, 78.2 MB/s ll /mnt/ext3/sdb9_backup_of_backup_of_xfs1.img -rw-r--r-- 1 root root 313M Jul 11 16:15 /mnt/ext3/sdb9_backup_of_backup_of_xfs1.img
compresses/packs quiet well 🙂 1/3rd of the size of the original data.
now you could transfer your backup to some remote destination… via ssh and rsync.
restore works like this:
gunzip -c /mnt/ext3/sdb9_backup_of_backup_of_xfs1.img | pv | dd of=/dev/sdb9
Cumulative Mode for xfsrestore
The cumulative mode of xfsresto re allows file system restoration from a specific incremental backup, for example, level 1 to level 9. To restore a file system from an incremental backup, simply add the -r option:
# xfsrestore -f /dev/st0 -S session-ID -r /path/to/destination
Interactive Operation
The xfsrestore utility also allows specific files from a dump to be extracted, added, or deleted. To use xfsrestore interactively, use the -i option, as in:
xfsrestore -f /dev/st0 -i /destination/directory
The interactive dialogue will begin after xfsrestore finishes reading the specified device. Available commands in this dialogue include cd , l s, add , delete, and extract
Links:
https://docs.oracle.com/cd/E37670_01/E37355/html/ol_burest_xfs.html
https://people.eecs.berkeley.edu/~kubitron/cs262/handouts/papers/hellwig.pdf
liked this article?
- only together we can create a truly free world
- plz support dwaves to keep it up & running!
- (yes the info on the internet is (mostly) free but beer is still not free (still have to work on that))
- really really hate advertisement
- contribute: whenever a solution was found, blog about it for others to find!
- talk about, recommend & link to this blog and articles
- thanks to all who contribute!
