“floating point arithmetic is considered an esoteric subject by many people” (src: What Every Computer Scientist Should Know About Floating Point Arithmetic – David Goldberg 1991.pdf)
some even do “transcendental calculations” (src)
make no mistake: computer make mistakes too!
not only humans make mistakes, computers make mistakes too, especially rounding errors or “representation” errors, because computers (up to this date no mass produced quantum computer is available) operate on 010101010101 (Binary for Decimal value of 1365).
1+1 in a computer might not be exactly 2
it might be more like 2.000001232 (which is not exactly 2, so one could say, computers are fast at calculations, but the results are sometimes WRONG.
Mr Goldberg’s explanation: “Squeezing infinitely many real numbers into a finite number of bits requires an approximate representation.” (src)
Approximations might be okay for computer games, but it is fatal for other applications such as accounting or science and space travel, where exact results are important, this remains a challenge up to date (in which some programming languages fare better (Perl) than others (JS) or need to use special libraries and tools to work around the challenge).
ESA’s Ariane 5 (1996) rocket exploded because of exactly such number conversion error.
(NASA had also their fair share of expensive software errors)
The solution might be…
either:
- avoid floats all together and use two ints (before the 123.123 and after the . )
- “Binary Coded Decimals” (needs more bits = slower, but at least the numbers are without rounding errors)
- might have more answers to this question: What-Every-Computer-Scientist-Should-Know-About-Floating-Point-Arithmetic-David-Goldberg-1991
“In 1972, the U.S. Supreme Court overturned a lower court decision which had allowed a patent for converting BCD encoded numbers to binary on a computer. This was an important case in determining the patentability of software and algorithms.” (src)
Numerical Computation Guide
this content was originally here:
http://cch.loria.fr/documentation/IEEE754/numerical_comp_guide/index.html
was backuped here: (thanks!)
and then moved here: (probably the most up to date version)
https://docs.oracle.com/cd/E60778_01/html/E60763/z4000ac020515.html
some of it is now here…
Contents
Preface
1. Introduction
2. IEEE Arithmetic
- IEEE Arithmetic Model
- IEEE Formats
- Storage Formats
- Single Format
- Double Format
- Double-Extended Format (SPARC and PowerPC)
- Double-Extended Format (Intel)
- Ranges and Precisions in Decimal Representation
- Underflow
3. The Math Libraries
- Standard Math Library
- Additional Math Libraries
- Single, Double, and Long Double Precision
- IEEE Support Functions
- ieee_functions(3m) and ieee_sun(3m)
- ieee_values(3m)
- ieee_flags(3m)
- ieee_retrospective(3m)
- nonstandard_arithmetic(3m)
- Implementation Features of libm and libsunmath
- About the Algorithms
- Argument Reduction for Trigonometric Functions
- Data Conversion Routines
- Random Number Facilities
- libc Support Functions
4. Exceptions and Exception Handling
- What Is an Exception?
- Detecting Exceptions
- Locating an Exception
- Using the Debuggers to Locate an Exception
- Using a Signal Handler to Locate an Exception
- ieee_handler (3m)
- Handling Exceptions
A. Examples
- IEEE Arithmetic
- Examining Stored IEEE hexadecimal Representations
- The Math Libraries
- Random Number Generator
- ieee_values
- ieee_flags — Rounding Direction
- Exceptions and Exception Handling
- ieee_handler — Trapping Exceptions
- ieee_handler — Abort on Exceptions
- Miscellaneous
B. SPARC Behavior and Implementation
- Floating-point Hardware
- fpversion(1) Function — Finding Information About the FPU
- Floating-Point Hardware–Disable/Enable
C. Intel Behavior and Implementation
D. PowerPC Behavior and Implementation
- Floating-Point Operations in the PowerPC Architecture
- Floating-Point Status and Control Register
- Floating-point Exceptions and Unimplemented Floating-Point Instructions
- Gradual Underflow
- Example: Using Fused Multiply-Add
E. What Every Computer Scientist Should Know About Floating Point Arithmetic
- Abstract
- Introduction
- Rounding Error
- Floating-point Formats
- Relative Error and Ulps
- Guard Digits
- Cancellation
- Exactly Rounded Operations
- The IEEE Standard
- Formats and Operations
- Special Quantities
- NaNs
- Exceptions, Flags and Trap Handlers
- Systems Aspects
- Instruction Sets
- Languages and Compilers
- Exception Handling
- The Details
- Rounding Error
- Binary to Decimal Conversion
- Errors In Summation
- Summary
- Acknowledgments
- References
- Theorem 14 and Theorem 8
- Theorem 14
- Proof
F. Standards Compliance
- SVID History
- IEEE 754 History
- SVID Future Directions
- SVID Implementation
- General Notes on Exceptional Cases and libm Functions
- Notes on libm
G. References
- Chapter 2: “IEEE Arithmetic”
- Chapter 3: “The Math Libraries”
- Chapter 4: “Exceptions and Signal Handling”
- Appendix B: “SPARC Behavior and Implementation”
- Appendix D: “PowerPC Behavior and Implementation”
- Standards
- Test Programs
Glossary
Index
This manual describes the floating-point software and hardware for the SPARC®, Intel®, and PowerPCTM (processor-based system) architectures.
It is primarily a reference manual designed to accompany SunTM language products.
Certain aspects of the IEEE Standard for Binary Floating-Point Arithmetic are discussed in this manual. To learn about IEEE arithmetic, see the 18-page Standard. See Appendix G, “References,” on page 237, for a brief bibliography on IEEE arithmetic.
This guide describes the floating-point environment supported through a combination of software and hardware by the Solaris operating system running on SPARC, Intel, and PowerPC systems.
This guide refers to compiler products that are components of the Sun WorkShop CompilersTM 4.2 release.
< Operating Environments
Sun WorkShop Compilers 4.2, described here, run under Solaris 2.x operating environment for SPARC, Intel, and PowerPC systems.
< Audience
This manual is written for those who develop, maintain, and port mathematical and scientific applications or benchmarks. Before using this manual, you should be familiar with the programming language used (FORTRAN, C, etc.), dbx (the source-level debugger), and the operating system commands and concepts.
< Organization
- Chapter 1, “Introduction,” introduces the floating-point environment.
- Chapter 2, “IEEE Arithmetic,” describes the IEEE arithmetic model, IEEE formats, and underflow.
- Chapter 3, “The Math Libraries,” describes the mathematics libraries provided with Sun WorkShop Compilers 4.2.
- Chapter 4, “Exceptions and Exception Handling,” describes exceptions and shows how to detect, locate, and handle them.
- Appendix A, “Examples,” contains example programs.
- Appendix B, “SPARC Behavior and Implementation,” describes the floating-point hardware options for SPARC workstations.
- Appendix C, “Intel Behavior and Implementation,” lists Intel and SPARC compatibility issues related to the floating-point units used in Intel systems.
- Appendix D, “PowerPC Behavior and Implementation,” discusses features and compatibility issues specific to the floating-point arithmetic implemented in PowerPC systems.
- Appendix E, “What Every Computer Scientist Should Know About Floating Point Arithmetic,” is an edited reprint of a paper by David Goldberg that is a tutorial on floating-point arithmetic.
- Appendix F, “Standards Compliance,” discusses standards compliance.
- Appendix G, “References,” includes a list of references and related documentation.
- “Glossary,” contains a definition of terms.
The examples in this manual are in C and FORTRAN, but the concepts apply for either compiler on a SPARC, Intel, or PowerPC system.
The David Goldberg paper is now Appendix E, “What Every Computer Scientist Should Know About Floating Point Arithmetic,” in this guide.
< Typographic Convention
The following table describes the typographic conventions used in this book.
< Shell Prompts in Command Examples
The following table shows the default system prompt and superuser prompt for the C shell, Bourne shell, and Korn shell.
| Shell | Prompt |
| C shell prompt | machine_name% |
| C shell superuser prompt | machine_name# |
| Bourne shell and Korn shell prompt | $ |
| Bourne shell and Korn shell superuser prompt | # |
Introduction |
1 |
 |
Sun’s floating-point environment on SPARC, Intel, and PowerPCTM, systems enables you to develop robust, high-performance, portable numerical applications.
The floating-point environment can also help investigate unusual behavior of numerical programs written by others.
These systems implement the arithmetic model specified by IEEE Standard 754 for Binary Floating Point Arithmetic.
This manual explains how to use the options and flexibility provided by the IEEE Standard on these systems.
< Floating-Point Environment
The floating-point environment consists of data structures and operations made available to the applications programmer by hardware, system software, and software libraries that together implement IEEE Standard 754.
IEEE Standard 754 makes it easier to write numerical applications.
It is a solid, well-thought-out basis for computer arithmetic that advances the art of numerical programming.
For example, the hardware provides storage formats corresponding to the IEEE data formats, operations on data in such formats, control over the rounding of results produced by these operations, status flags indicating the occurrence of IEEE numeric exceptions, and the IEEE-prescribed result when such an exception occurs in the absence of a user-defined handler for it. System software supports IEEE exception handling. The software libraries, including the math libraries, libm and libsunmath, implement functions such as exp(x) and sin(x) in a way that follows the spirit of IEEE Standard 754 with respect to the raising of exceptions. (When a floating-point arithmetic operation has no well-defined result, the system communicates this fact to the user by raising an exception.) The math libraries also provide function calls that handle special IEEE values like Inf (infinity) or NaN (Not a Number).
The three constituents of the floating-point environment interact in subtle ways, and those interactions are generally invisible to the applications programmer. The programmer sees only the computational mechanisms prescribed or recommended by the IEEE standard. In general, this manual guides programmers to make full and efficient use of the IEEE mechanisms so that they can write application software effectively.
Many questions about floating-point arithmetic concern elementary operations on numbers. For example,
- What is the result of an operation when the infinitely precise result is not representable in the computer system?
- Are elementary operations like multiplication and addition commutative?
Another class of questions is connected to exceptions and exception handling.
For example, what happens when you:
- Multiply two very large numbers?
- Divide by zero?
- Attempt to compute the square root of a negative number?
In some other arithmetics, the first class of questions might not have the expected answers, or the exceptional cases in the second class are treated the same: the program aborts on the spot; in some very old machines, the computation proceeds, but with garbage.
The IEEE Standard 754 ensures that operations yield the mathematically expected results with the expected properties. It also ensures that exceptional cases yield specified results, unless the user specifically makes other choices.
In this manual, there are references to terms like NaN or subnormal number. The “Glossary” on page 243, defines terms related to floating-point arithmetic.
This chapter discusses the IEEE Standard 754, the arithmetic model specified by the IEEE Standard for Binary Floating-Point Arithmetic (IEEE Standard for Binary Floating-Point Arithmetic, ANSI/IEEE Std 754-1985 (IEEE 754)). All SPARC, Intel, and PowerPC computers use IEEE arithmetic. All Sun compiler products support the features of IEEE arithmetic.
This chapter is organized into the following sections:
| IEEE Arithmetic Model | page 3 |
| IEEE Formats | page 5 |
| Underflow | page 22 |
< IEEE Arithmetic Model
This section describes the IEEE Standard 754 specification.
What Is IEEE Arithmetic?
The IEEE Standard 754 specifies:
- The IEEE single format has a precision of 24 bits (24-bit significands), and 32 bits overall. The IEEE double format has a precision of 53 bits, and 64 bits overall.
- Any format in the class of IEEE double extended formats has a precision at least of 64 bits, and at least 79 bits overall.
- Accuracy requirements on floating-point operations: add, subtract, multiply, divide, square root, remainder, round numbers in floating-point format to integer values, convert between different floating-point formats, convert between floating-point and integer formats, and compare.
- The remainder and compare operations must be exact. Each of the other operations must deliver to its destination the exact result, unless there is no such result; or that result does not fit in the destination’s format. In the latter case, the operation must minimally modify the exact result according to the rules of prescribed rounding modes, presented below, and deliver the result so modified to the operation’s destination.
- Accuracy, monotonicity and identity requirements for conversions between decimal strings and binary floating-point numbers in either of the basic floating-point formats.
- For operands lying within specified ranges, these conversions must produce exact results, if possible, or minimally modify such exact results in accordance with the rules of the prescribed rounding modes. For operands not lying within the specified ranges, these conversions must produce results that differ from the exact result by no more than a specified tolerance that depends on the rounding mode.
- Five types of IEEE floating-point exceptions, and the conditions for indicating to the user the occurrence of exceptions of these types.
- The five types of floating-point exceptions are invalid operation, division by zero, overflow, underflow, and inexact.
- Four rounding directions: toward the nearest representable value, with “even” values preferred whenever there are two nearest representable values; toward –
 (down); toward + (up); and toward 0 (chop).
(down); toward + (up); and toward 0 (chop). - Rounding precision; for example, if a system delivers results in double extended format, the user should be able to specify that such results are to be rounded to the precision of either basic format, with trailing zeros.
The Standard supports user handling of exceptions, rounding, and precision. Consequently, the Standard supports interval arithmetic, and diagnosis of anomalies. The IEEE Standard 754 makes it possible to standardize elementary functions like exp and cos, to create very high-precision arithmetic, and to couple numerical and symbolic algebraic computation.
IEEE Standard 754 floating-point arithmetic offers users greater control over computation than does any other kind of floating-point arithmetic. The IEEE Standard 754 simplifies the task of writing numerically sophisticated, portable programs not only by imposing rigorous requirements on conforming implementations. The Standard also allows such implementations to provide refinements and enhancements to the Standard itself.
< IEEE Formats
This section describes how floating-point data is stored in memory. It summarizes the precisions and ranges of the different IEEE storage formats.
Storage Formats
A floating-point format is a data structure specifying the fields that comprise a floating-point numeral, the layout of those fields, and their arithmetic interpretation. A floating-point storage format specifies how a floating-point format is stored in memory. The IEEE standard defines the formats, but it leaves to implementors the choice of storage formats.
Assembly language software sometimes relies on using the storage formats, but higher level languages usually deal only with the linguistic notions of floating-point data types. These types have different names in different high-level languages, and correspond to the IEEE formats as shown in Table 2-1.
| IEEE Precision | C, C++ |
FORTRAN |
| single | float | REAL or REAL*4 |
| double | double | DOUBLE PRECISION or REAL*8 |
| double | long double | REAL*16 |
IEEE Standard 754 specifies exactly the single and double floating-point formats, and it defines a class of extended formats for each of these two basic formats. The format called double extended in Table 2-1 is one of the class of double extended formats defined by the IEEE standard.
The following sections describe in detail each of the three storage formats used for the IEEE floating-point formats.
Single Format
The IEEE single format consists of three fields: a 23-bit fraction, f; an 8-bit biased exponent, e; and a 1-bit sign, s. These fields are stored contiguously in one 32-bit word, as shown in Figure 2-1. Bits 0:22 contain the 23-bit fraction, f, with bit 0 being the least significant bit of the fraction and bit 22 being the most significant; bits 23:30 contain the 8-bit biased exponent, e, with bit 23 being the least significant bit of the biased exponent and bit 30 being the most significant; and the highest-order bit 31 contains the sign bit, s.
Figure 2-1 Single-Storage Format

Table 2-2 shows the correspondence between the values of the three constituent fields s, e and f, on the one hand, and the value represented by the single- format bit pattern on the other; u means don’t care, that is, the value of the indicated field is irrelevant to the determination of the value of the particular bit patterns in single format.
Notice that when e < 255, the value assigned to the single format bit pattern is formed by inserting the binary radix point immediately to the left of the fraction’s most significant bit, and inserting an implicit bit immediately to the left of the binary point, thus representing in binary positional notation a mixed number (whole number plus fraction, wherein 0 <= fraction < 1).
The mixed number thus formed is called the single-format significand. The implicit bit is so named because its value is not explicitly given in the single- format bit pattern, but is implied by the value of the biased exponent field.
For the single format, the difference between a normal number and a subnormal number is that the leading bit of the significand (the bit to left of the binary point) of a normal number is 1, whereas the leading bit of the significand of a subnormal number is 0. Single-format subnormal numbers were called single-format denormalized numbers in IEEE Standard 754.
The 23-bit fraction combined with the implicit leading significand bit provides 24 bits of precision in single-format normal numbers.
Examples of important bit patterns in the single-storage format are shown in Table 2-3. The maximum positive normal number is the largest finite number representable in IEEE single format. The minimum positive subnormal number is the smallest positive number representable in IEEE single format. The minimum positive normal number is often referred to as the underflow threshold. (The decimal values for the maximum and minimum normal and subnormal numbers are approximate; they are correct to the number of figures shown.)
A NaN (Not a Number) can be represented with any of the many bit patterns that satisfy the definition of a NaN. The hex value of the NaN shown in Table 2-3 is just one of the many bit patterns that can be used to represent a NaN.
Double Format
The IEEE double format consists of three fields: a 52-bit fraction, f; an 11-bit biased exponent, e; and a 1-bit sign, s. These fields are stored contiguously in two successively addressed 32-bit words, as shown in Figure 2-2.
In the SPARC architecture, the higher address 32-bit word contains the least significant 32 bits of the fraction, while in the Intel and PowerPC architectures the lower address 32-bit word contains the least significant 32 bits of the fraction.
If we denote f[31:0] the least significant 32 bits of the fraction, then bit 0 is the least significant bit of the entire fraction and bit 31 is the most significant of the 32 least significant fraction bits.
In the other 32-bit word, bits 0:19 contain the 20 most significant bits of the fraction, f[51:32], with bit 0 being the least significant of these 20 most significant fraction bits, and bit 19 being the most significant bit of the entire fraction; bits 20:30 contain the 11-bit biased exponent, e, with bit 20 being the least significant bit of the biased exponent and bit 30 being the most significant; and the highest-order bit 31 contains the sign bit, s.
Figure 2-2 numbers the bits as though the two contiguous 32-bit words were one 64-bit word in which bits 0:51 store the 52-bit fraction, f; bits 52:62 store the 11-bit biased exponent, e; and bit 63 stores the sign bit, s.

Figure 2-2 Double-Storage Format
The values of the bit patterns in these three fields determine the value represented by the overall bit pattern.
Table 2-4 shows the correspondence between the values of the bits in the three constituent fields, on the one hand, and the value represented by the double- format bit pattern on the other; u means don’t care, because the value of the indicated field is irrelevant to the determination of value for the particular bit pattern in double format.
Notice that when e < 2047, the value assigned to the double-format bit pattern is formed by inserting the binary radix point immediately to the left of the fraction’s most significant bit, and inserting an implicit bit immediately to the left of the binary point. The number thus formed is called the significand. The implicit bit is so named because its value is not explicitly given in the double- format bit pattern, but is implied by the value of the biased exponent field.
For the double format, the difference between a normal number and a subnormal number is that the leading bit of the significand (the bit to the left of the binary point) of a normal number is 1, whereas the leading bit of the significand of a subnormal number is 0. Double-format subnormal numbers were called double-format denormalized numbers in IEEE Standard 754.
The 52-bit fraction combined with the implicit leading significand bit provides 53 bits of precision in double-format normal numbers.
Examples of important bit patterns in the double-storage format are shown in Table 2-5. The bit patterns in the second column appear as two 8-digit hexadecimal numbers. For the SPARC architecture, the left one is the value of the lower addressed 32-bit word, and the right one is the value of the higher addressed 32-bit word, while for the Intel and PowerPC architectures, the left one is the higher addressed word, and the right one is the lower addressed word. The maximum positive normal number is the largest finite number representable in the IEEE double format. The minimum positive subnormal number is the smallest positive number representable in IEEE double format. The minimum positive normal number is often referred to as the underflow threshold. (The decimal values for the maximum and minimum normal and subnormal numbers are approximate; they are correct to the number of figures shown.)
A NaN (Not a Number) can be represented by any of the many bit patterns that satisfy the definition of NaN. The hex values of the NaN shown in Table 2-5 is just one of the many bit patterns that can be used to represent a NaN.
Double-Extended Format (SPARC and PowerPC)
These floating-point environment’s quadruple-precision format conforms to the IEEE definition of double-extended format.
The quadruple-precision format occupies four 32-bit words and consists of three fields:
a 112-bit fraction, f;
a 15-bit biased exponent, e;
and a 1-bit sign, s.
These are stored contiguously as shown in Figure 2-3.
In the SPARC architecture, the highest addressed 32-bit word contains the least significant 32-bits of the fraction, denoted f[31:0], while in the PowerPC architecture, the lowest addressed 32-bit word contains these bits.
The next two 32-bit words (counting downwards on SPARC architecture and upwards on PowerPC architectures) contain f[63:32] and f[95:64], respectively.
Bits 0:15 of the next word contain the 16 most significant bits of the fraction, f[111:96], with bit 0 being the least significant of these 16 bits, and bit 15 being the most significant bit of the entire fraction.
Bits 16:30 contain the 15-bit biased exponent, e, with bit 16 being the least significant bit of the biased exponent and bit 30 being the most significant; and bit 31 contains the sign bit, s.
Figure 2-3 numbers the bits as though the four contiguous 32-bit words were one 128-bit word in which bits 0:111 store the fraction, f; bits 112:126 store the 15-bit biased exponent, e; and bit 127 stores the sign bit, s.
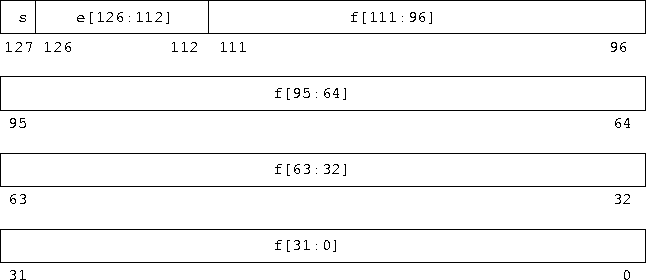
Figure 2-3 Double-Extended Format (SPARC and PowerPC)
The values of the bit patterns in the three fields f, e, and s, determine the value represented by the overall bit pattern.
Table 2-6 shows the correspondence between the values of the three constituent fields and the value represented by the bit pattern in quadruple-precision format. u means don’t care, because the value of the indicated field is irrelevant to the determination of values for the particular bit patterns.
Examples of important bit patterns in the quadruple-precision double-extended storage format are shown in Table 2-7. The bit patterns in the second column appear as four 8-digit hexadecimal numbers. For the SPARC architecture, the left-most number is the value of the lowest addressed 32-bit word, and the right-most number is the value of the highest addressed 32-bit word, while for the PowerPC architecture, the left number is the highest addressed word, and the right number is the lowest addressed word. The maximum positive normal number is the largest finite number representable in the quadruple precision format. The minimum positive subnormal number is the smallest positive number representable in the quadruple precision format. The minimum positive normal number is often referred to as the underflow threshold. (The decimal values for the maximum and minimum normal and subnormal numbers are approximate; they are correct to the number of figures shown.)
The hex values of the NaNs shown in Table 2-7 are just two of the many bit patterns that can be used to represent NaNs.
Double-Extended Format (Intel)
This floating-point environment’s double-extended format conforms to the IEEE definition of double-extended formats. It consists of four fields: a 63-bit fraction, f; a 1-bit explicit leading significand bit, j; a 15-bit biased exponent, e; and a 1-bit sign, s.
In the family of Intel architectures, these fields are stored contiguously in ten successively addressed 8-bit bytes. However, the UNIX System V Application Binary Interface Intel 386 Processor Supplement (Intel ABI) requires that double-extended parameters and results occupy three consecutively addressed 32-bit words in the stack, with the most significant 16 bits of the highest addressed word being unused, as shown in Figure 2-4.
The lowest addressed 32-bit word contains the least significant 32 bits of the fraction, f[31:0], with bit 0 being the least significant bit of the entire fraction and bit 31 being the most significant of the 32 least significant fraction bits. In the middle addressed 32-bit word, bits 0:30 contain the 31 most significant bits of the fraction, f[62:32], with bit 0 being the least significant of these 31 most significant fraction bits, and bit 30 being the most significant bit of the entire fraction; bit 31 of this middle addressed 32-bit word contains the explicit leading significand bit, j.
In the highest addressed 32-bit word, bits 0:14 contain the 15-bit biased exponent, e, with bit 0 being the least significant bit of the biased exponent and bit 14 being the most significant; and bit 15 contains the sign bit, s. Although the highest order 16 bits of this highest addressed 32-bit word are unused by the family of Intel architectures, their presence is essential for conformity to the Intel ABI, as indicated above.
Figure 2-4 numbers the bits as though the three contiguous 32-bit words were one 96-bit word in which bits 0:62 store the 63-bit fraction, f; bit 63 stores the explicit leading significand bit, j; bits 64:78 store the 15-bit biased exponent, e; and bit 79 stores the sign bit, s.
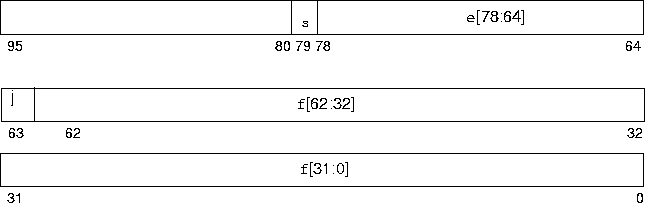
Figure 2-4 Double-Extended Format (Intel)
The values of the bit patterns in the four fields f, j, e and s, determine the value represented by the overall bit pattern.
Table 2-8 shows the correspondence between the counting number values of the four constituent field and the value represented by the bit pattern. u means don’t care, because the value of the indicated field is irrelevant to the determination of value for the particular bit patterns.
Notice that bit patterns in double-extended format do not have an implicit leading significand bit. The leading significand bit is given explicitly as a separate field, j, in the double-extended format. However, when e is nonzero, any bit pattern with j = 0 is unsupported in the sense that using such a bit pattern as an operand in floating-point operations provokes an invalid operation exception.
The union of the disjoint fields j and f in the double extended format is called the significand. When e < 32767 and j = 1, or when e = 0 and j = 0, the significand is formed by inserting the binary radix point between the leading significand bit, j, and the fraction’s most significant bit.
For the double-extended format, the difference between a normal number and a subnormal number is that the explicit leading bit of the significand of a normal number is 1, whereas the explicit leading bit of the significand of a subnormal number is 0 and the biased exponent field e must also be 0. Subnormal numbers in double-extended format were called double-extended format denormalized numbers in IEEE Standard 754.
Examples of important bit patterns in the double-extended storage format appear in Table 2-9. The bit patterns in the second column appear as one
4-digit hexadecimal counting number, which is the value of the 16 least significant bits of the highest addressed 32-bit word (recall that the most significant 16 bits of this highest addressed 32-bit word are unused, so their value is not shown), followed by two 8-digit hexadecimal counting numbers, of which the left one is the value of the middle addressed 32-bit word, and the right one is the value of the lowest addressed 32-bit word. The maximum positive normal number is the largest finite number representable in the Intel double-extended format. The minimum positive subnormal number is the smallest positive number representable in the double-extended format. The minimum positive normal number is often referred to as the underflow threshold. (The decimal values for the maximum and minimum normal and subnormal numbers are approximate; they are correct to the number of figures shown.)
A NaN (Not a Number) can be represented by any of the many bit patterns that satisfy the definition of NaN. The hex values of the NaNs shown in Table 2-9 illustrate that the leading (most significant) bit of the fraction field determines whether a NaN is quiet (leading fraction bit = 1) or signaling (leading fraction bit = 0).
Ranges and Precisions in Decimal Representation
This section covers the notions of range and precision for a given storage format. It includes the ranges and precisions corresponding to the IEEE single and double formats, and to the implementations of IEEE double-extended format to SPARC, PowerPC, and Intel architectures. In explaining the notions of range and precision, reference is made to the IEEE single format.
The IEEE standard specifies that 32 bits be used to represent a floating point number in single format. Because there are only finitely many combinations of 32 zeroes and ones, only finitely many numbers can be represented by 32 bits.
- What are the decimal representations of the largest and smallest positive numbers that can be represented in this particular format?
Rephrase the question and introduce the notion of range:
- What is the range, in decimal notation, of numbers that can be represented by the IEEE single format?
Taking into account the precise definition of IEEE single format, you can prove that the range of floating-point numbers that can be represented in IEEE single format (if restricted to positive normalized numbers) is as follows:
1.175...x (10-38) to 3.402...x (10+38)
A second question refers to the precision (or as many people refer to it, the accuracy, or the number of significant digits) of the numbers represented in a given format. These notions are explained by looking at some pictures and examples.
The IEEE standard for binary floating-point arithmetic specifies the set of numerical values representable in the single format. Remember that this set of numerical values is described as a set of binary floating-point numbers. The significand of the IEEE single format has 23 bits, which together with the implicit leading bit, yield 24 digits (bits) of (binary) precision.
You obtain a different set of numerical values by marking the numbers:
x = (x1.x2x3...xq) x (10n)
(representable by q decimal digits in the significand) on the number line.
Figure 2-5 exemplifies this situation:
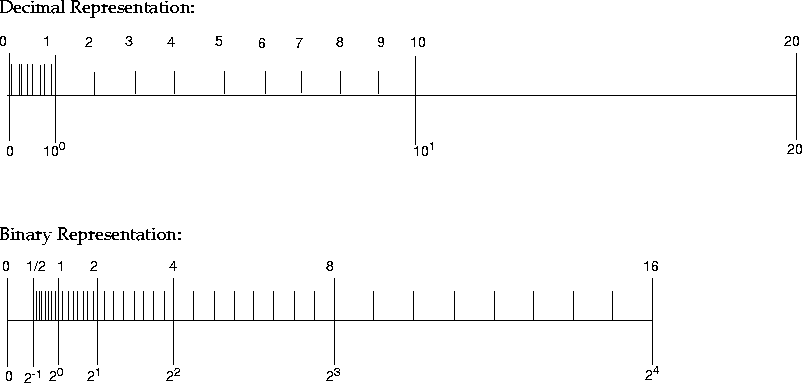
Figure 2-5 Comparison of a Set of Numbers Defined by
Digital and Binary Representation
Notice that the two sets are different. Therefore, estimating the number q of significant decimal digits corresponding to 24 significant binary digits, requires reformulating the problem.
Reformulate the problem in terms of converting floating-point numbers between binary representations (the internal format used by the computer) and the decimal format (the format users are usually interested in). In fact, you may want to convert from decimal to binary and back to decimal, as well as convert from binary to decimal and back to binary.
It is important to notice that because the sets of numbers are different, conversions are in general inexact. If done correctly, converting a number from one set to a number in the other set results in choosing one of the two neighboring numbers from the second set (which one specifically is a question related to rounding).
Consider some examples. Assume you are trying to represent the number with the following decimal representation in IEEE single format:
x = x1.x2 x3... x 10n
In the above example, the information contained in x has to be coded in a 32-bit word. Generally, this might be impossible (if there are too many digits in x), for example, some of the information might not fit in 32 bits. For example, use:
y = 838861.2, z = 1.3
and run the following FORTRAN program:
REAL Y, Z
Y = 838861.2
Z = 1.3
WRITE(*,40) Y
40 FORMAT("y: ",1PE18.11)
WRITE(*,50) Z
50 FORMAT("z: ",1PE18.11)
|
The output from this program should be similar to:
y: 8.38861187500E+05 z: 1.29999995232E+00 |
The difference between the value 8.388612 x 105 assigned to y and the value printed out is 0.000000125, which is seven decimal orders of magnitude smaller than y. The accuracy of representing y in IEEE single format is about 6 to 7 significant digits, or that y has about six significant digits if it is to be represented in IEEE single format.
Similarly, the difference between the value 1.3 assigned to z and the value printed out is 0.00000004768, which is eight decimal orders of magnitude smaller than z. The accuracy of representing z in IEEE single format is about 7 to 8 significant digits, or that z has about seven significant digits if it is to be represented in IEEE single format.
- Assume you convert a decimal floating point number a to its IEEE single format binary representation b, and then translate b back to a decimal number c; how many orders of magnitude are between a and a – c?
- What is the number of significant decimal digits of a in the IEEE single format representation, or how many decimal digits are to be trusted as accurate when one represents x in IEEE single format?
The number of significant decimal digits is always between 6 and 9, that is, at least 6 digits, but not more than 9 digits are accurate (with the exception of cases when the conversions are exact, when infinitely many digits could be accurate).
Conversely, if you convert a binary number in IEEE single format to a decimal number, and then convert it back to binary, generally, you need to use at least 9 decimal digits to ensure that after these two conversions you obtain the number you started from.
The complete picture is given in Table 2-10:
< Underflow
Underflow occurs, roughly speaking, when the result of an arithmetic operation is so small that it cannot be stored in its intended destination format without suffering a rounding error that is larger than usual.
Underflow Thresholds
Table 2-11 shows the underflow thresholds for single, double, and double-extended precision.
The positive subnormal numbers are those numbers between the smallest normal number and zero. Subtracting two (positive) tiny numbers that are near the smallest normal number might produce a subnormal number. Or, dividing the smallest positive normal number by two produces a subnormal result.
The presence of subnormal numbers provides greater precision to floating-point calculations that involve small numbers, although the subnormal numbers themselves have fewer bits of precision than normal numbers. Producing subnormal numbers (rather than returning the answer zero) when the mathematically correct result has magnitude less than the smallest positive normal number is known as gradual underflow.
There are several other ways to deal with such underflow results. One way, common in the past, was to flush those results to zero. This method is known as Store 0 and was the default on most mainframes before the advent of the IEEE Standard.
The mathematicians and computer designers who drafted IEEE Standard 754 considered several alternatives while balancing the desire for a mathematically robust solution with the need to create a standard that could be implemented efficiently.
How Does IEEE Arithmetic Treat Underflow?
IEEE Standard 754 chooses gradual underflow as the preferred method for dealing with underflow results. This method amounts to defining two representations for stored values, normal and subnormal.
Recall that the IEEE format for a normal floating-point number is:
The smallest positive normal number that can be stored, then, has the negative exponent of greatest magnitude and a fraction of all zeros. Even smaller numbers can be accommodated by considering the leading bit to be zero rather than one. In the double-precision format, this effectively extends the minimum exponent from 10-308 to 10-324, because the fraction part is 52 bits long (roughly 16 decimal digits.) These are the subnormal numbers; returning a subnormal number (rather than flushing an underflowed result to zero) is gradual underflow.
Clearly, the smaller a subnormal number, the fewer nonzero bits in its fraction; computations producing subnormal results do not enjoy the same bounds on relative roundoff error as computations on normal operands. However, the key fact about gradual underflow is that its use implies:
- Underflowed results need never suffer a loss of accuracy any greater than that which results from ordinary roundoff error.
- Addition, subtraction, comparison, and remainder are always exact when the result is very small.
Recall that the IEEE format for a subnormal floating-point number is:
Gradual underflow allows you to extend the lower range of representable numbers. It is not smallness that renders a value questionable, but its associated error. Algorithms exploiting subnormal numbers have smaller error bounds than other systems. The next section provides some mathematical justification for gradual underflow.
Why Gradual Underflow?
The purpose of subnormal numbers is not to avoid underflow/overflow entirely, as some other arithmetic models do. Rather, subnormal numbers eliminate underflow as a cause for concern for a variety of computations (typically, multiply followed by add). For a more detailed discussion, see “Underflow and the Reliability of Numerical Software” by James Demmel and “Combatting the Effects of Underflow and Overflow in Determining Real Roots of Polynomials” by S. Linnainmaa.
The presence of subnormal numbers in the arithmetic means that untrapped underflow (which implies loss of accuracy) cannot occur on addition or subtraction. If x and y are within a factor of two, then x – y is error-free. This is critical to a number of algorithms that effectively increase the working precision at critical places in algorithms.
In addition, gradual underflow means that errors due to underflow are no worse than usual roundoff error. This is a much stronger statement than can be made about any other method of handling underflow, and this fact is one of the best justifications for gradual underflow.
Error Properties of Gradual Underflow
Most of the time, floating-point results are rounded:
In IEEE arithmetic, with rounding mode to nearest,
 roundoff
roundoff ulp is an acronym for Unit in the Last Place. The least significant bit of the fraction of a number in its standard representation, is the last place. If the roundoff error is less than or equal to one half unit in the last place, then the calculation is correctly rounded.
For example, an ulp of unity for each floating point data type would be as shown in Table 2-12:
| Precision | Value |
| single | ulp(1) = 2-23 ~ 1.192092896e-07 |
| double | ulp(1) = 2-52 ~ 2.22044604925031308e-16 |
| quadruple | ulp(1) = 2-113 ~ 1.92592994438723585305597794258492732e-34 |
Recall that only a finite set of numbers can be exactly represented in any computer arithmetic. As the magnitudes of numbers get smaller and approach zero, the gap between neighboring representable numbers never widens but narrows. Conversely, as the magnitude of numbers gets larger, the gap between neighboring representable numbers widens.
For example, imagine you are using a binary arithmetic that has only 3 bits of precision. Then, between any two powers of 2, there are 23 = 8 representable numbers, as shown in Figure 2-6.
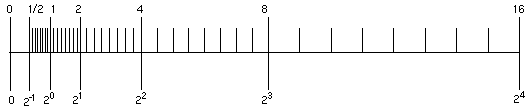
Figure 2-6 Number Line
The number line shows how the gap between numbers doubles from one exponent to the next.
In the IEEE single format, the difference in magnitude between the two smallest positive subnormal numbers is approximately 10-45, whereas the difference in magnitude between the two largest finite numbers is approximately 1031!
In Table 2-13, nextafter(x,+) denotes the next representable number after x as you move along the number line towards +.
Any conventional set of representable floating-point numbers has the property that the worst effect of one inexact result is to introduce an error no worse than the distance to one of the representable neighbors of the computed result. When subnormal numbers are added to the representable set and gradual underflow is implemented, the worst effect of one inexact or underflowed result is to introduce an error no greater than the distance to one of the representable neighbors of the computed result.
In particular, in the region between zero and the smallest normal number, the distance between any two neighboring numbers equals the distance between zero and the smallest subnormal number. The presence of subnormal numbers eliminates the possibility of introducing a roundoff error that is greater than the distance to the nearest representable number.
Because no calculation incurs roundoff error greater than the distance to any of the representable neighbors of the computed result, many important properties of a robust arithmetic environment hold, including these three:
- x
 y
y  x
x -y 0 - (x-y) + y
 x, to within a rounding error in the larger of x and y
x, to within a rounding error in the larger of x and y - 1/(1/x) x, when x is a normalized number, implying 1/x 0
An alternative underflow scheme is Store 0, which flushes underflow results to zero. Store 0 violates the first and second properties whenever x-y underflows. Also, Store 0 violates the third property whenever 1/x underflows.
Let  represent the smallest positive normalized number, which is also known as the underflow threshold. Then the error properties of gradual underflow and Store 0 can be compared in terms of .
represent the smallest positive normalized number, which is also known as the underflow threshold. Then the error properties of gradual underflow and Store 0 can be compared in terms of .
gradual underflow: |error| < 1/2 ulp in
Store 0: |error|
There is a significant difference between 1/2 unit in the last place of , and itself.
Two Examples of Gradual Underflow Versus Store 0
The following are two well-known mathematical examples. The first example is an inner product.
sum = 0;
for (i = 0; i < n; i++) {
sum = sum + a[i] * y[i];
}
result = sum / n;
|
With gradual underflow, result is as accurate as roundoff allows. In Store 0, a small but nonzero sum could be delivered that looks plausible but is wrong in nearly every digit. However, in fairness, it must be admitted that to avoid just these sorts of problems, clever programmers scale their calculations if they are able to anticipate where minuteness might degrade accuracy.
The second example, deriving a complex quotient, isn’t amenable to scaling:
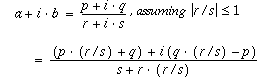
It can be shown that, despite roundoff, the computed complex result differs from the exact result by no more than what would have been the exact result if p + i · q and r + i · s each had been perturbed by no more than a few ulps.
This error analysis holds in the face of underflows, except that when both a and b underflow, the error is bounded by a few ulps of |a + i · b|. Neither conclusion is true when underflows are flushed to zero.
This algorithm for computing a complex quotient is robust, and amenable to error analysis, in the presence of gradual underflow. A similarly robust, easily analyzed, and efficient algorithm for computing the complex quotient in the face of Store 0 does not exist. In Store 0, the burden of worrying about low-level, complicated details shifts from the implementor of the floating-point environment to its users.
The class of problems that succeed in the presence of gradual underflow, but fail with Store 0, is larger than the fans of Store 0 may realize. Many frequently used numerical techniques fall in this class:
- Linear equation solving
- Polynomial equation solving
- Numerical integration
- Convergence acceleration
- Complex division
Does Underflow Matter?
Despite these examples, it can be argued that underflow rarely matters, and so, why bother? However, this argument turns upon itself.
In the absence of gradual underflow, user programs need to be sensitive to the implicit inaccuracy threshold. For example, in single precision, if underflow occurs in some parts of a calculation, and Store 0 is used to replace underflowed results with 0, then accuracy can be guaranteed only to around 10-31, not 10-38, the usual lower range for single-precision exponents.
This means that programmers need to implement their own method of detecting when they are approaching this inaccuracy threshold, or else abandon the quest for a robust, stable implementation of their algorithm.
Some algorithms can be scaled so that computations don’t take place in the constricted area near zero. However, scaling the algorithm and detecting the inaccuracy threshold can be difficult and time-consuming for each numerical program.
Links:
https://docs.oracle.com/cd/E60778_01/html/E60763/z4000ac020515.html
https://en.wikipedia.org/wiki/IEEE_754
liked this article?
- only together we can create a truly free world
- plz support dwaves to keep it up & running!
- (yes the info on the internet is (mostly) free but beer is still not free (still have to work on that))
- really really hate advertisement
- contribute: whenever a solution was found, blog about it for others to find!
- talk about, recommend & link to this blog and articles
- thanks to all who contribute!
