lsb_release -a; # tested with Description: Debian GNU/Linux 12 (bookworm) # previously this was tested with cat /etc/os-release |grep PRETTY PRETTY_NAME="Debian GNU/Linux 11 (bullseye)"
why?
duplicate files are a waste of disk space.
every system experiences catastrophic failures, slow downs and crashes of programs, when RAM or disk space runs out 😀
BUT: under no circumstances shall a program be designed, to allow accidents that delete ALL files 😀 (without saveguards like: “you will delete all fiels under this folder?” “are you sure?” “are you really sure?”
sometimes files are stored in a certain folder for a reason.
there are programs, that allow
- finding duplicate files
- then deleting one copy
- then setting a link to the still existing copy
= disk space is saved, and all files are still accessible via their folders
precautions: be careful!
developers make mistakes, users make mistakes, computers make mistakes.
things can go wrong fast, so it’s always good to:
- backup (and detach from any computer to not allow ransomeware access and store it double-triple-metall-shielded to avoid any dataloss due to electro-magnetism)
- backup (and detach from any computer to not allow ransomeware access and store it double-triple-metall-shielded to avoid any dataloss due to electro-magnetism)
- backup (and detach from any computer to not allow ransomeware access and store it double-triple-metall-shielded to avoid any dataloss due to electro-magnetism)
done that? scroll to continue X-D
how to find largest files?
very minimalistic pure bash (busybox approved) way:
vim /scripts/diskusage.sh #!/bin/bash if [ -z "$1" ] then # list 30 biggest files or directories (qnap-busybox tested) du -a / | sort -n -r | head -n 30; else du -a $1 | sort -n -r | head -n 30; fi # run it chmod +x /scripts/*.sh /scripts/diskusage.sh /home/user # another variant # du -sx /* | sort -rh | head -30;
hardlink
hardlink is a tool which replaces copies of a file with hardlinks, therefore it can be usefull for saving diskspace.
examples:
# start a test dry-run on the current directory
hardlink -v --dry-run .
it also per default searches in all subdirectories of the current directory:
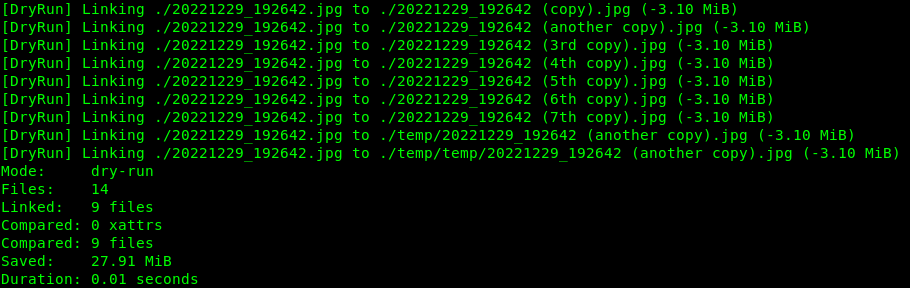
# do it for real
hardlink -v .
how much diskspace could be saved?
So how much can efficiently be salvaged if all duplicate data would be replaced with links (pointers) to the real data on disk?
# dryrun = test run (no modification to files) # how much hardlinking duplicate files could save disk space? # depending on amount of files and CPU power this will run for a while time hardlink -v --dry-run /home/user Mode: dry-run Method: sha256 Files: 634617 Linked: 54028 files Compared: 0 xattrs Compared: 5217072 files Saved: 107.06 GiB <- nice Duration: 1577.789062 seconds
how to find largest duplicate files?
no idea yet.
if a package manager with access to packages is possible (for Debian users it usually is):
su - root apt update apt install rmlint # there is also a (python based) gui for it # BUT 1) it's not ment to be run as root (LOADS OF WARNINGS!) # 2) as non-root it kind of "nothing found" malfunctioned # apt install rmlint-gui Ctrl+D # become non-root # test it out mkdir temp cd temp touch 1 2 3 time dd if=/dev/zero of=1GByte.zero.testfile bs=64M count=16 iflag=fullblock cp -rv 1GByte.zero.testfile 1GByte.zero.testfile.2 time rmlint . # Empty file(s): rm '/home/user/temp/1' rm '/home/user/temp/2' rm '/home/user/temp/3' # Duplicate(s): ls '/home/user/temp/1GByte.zero.testfile' rm '/home/user/temp/1GByte.zero.testfile.2' ==> Note: Please use the saved script below for removal, not the above output. ==> In total 7 files, whereof 1 are duplicates in 1 groups. ==> This equals 1.00 GB of duplicates which could be removed. ==> 3 other suspicious item(s) found, which may vary in size. ==> Scanning took in total 2.729s. Wrote a json file to: /home/user/temp/rmlint.json Wrote a sh file to: /home/user/temp/rmlint.sh real 0m2.742s # manpage: rmlint.man.txt # online documentation # for thrills run it on user's home dir # (no modifications just reporting, "dryrun" mode so some users says) time rmlint ~ # sample output: ==> Note: Please use the saved script below for removal, not the above output. ==> In total 505311 files, whereof 158835 are duplicates in 78903 groups. ==> This equals 137.71 GB of duplicates which could be removed. ==> 3603 other suspicious item(s) found, which may vary in size. ==> Scanning took in total 12m 30.727s. Wrote a sh file to: /home/user/rmlint.sh Wrote a json file to: /home/user/rmlint.json # it ran for 12m30.936s (i5 + ssd) on, rmlint reports runtime by default so no need to append time du -hs . 760GBytes of data
So in one’s case 18.11% of disk space saving would be possible 😀
It is interesting to note that “hardlinks” reports 14.08% of disk space save-able.
Where the difference comes from? One does not know (yet).
Thanks all involved!
jdupes
website: https://github.com/jbruchon/jdupes
WARNING: jdupes IS NOT a drop-in compatible replacement for fdupes!
identify and delete or link duplicate files
examples:
jdupes -m .
Scanning: 7 files, 1 items (in 1 specified)
6 duplicate files (in 1 sets), occupying 6 MB
-L --linkhard
replace all duplicate files with hardlinks to the first file in each set of duplicates
fdupes
identifies duplicate files within given directorie (fdupes.manpage.txt)
su - root; apt update; apt install fdupes;
-H --hardlinks normally, when two or more files point to the same disk area they are treated as non-duplicates; this option will change this behavior
examples:
fdupes -r -m .
8 duplicate files (in 1 sets), occupying 8.4 megabytes
rdfind
su - root; apt update; apt install rdfind; # dry run (no file is removed) rdfind -dryrun true ./search/in/this/folder # WARNING! THIS REMOVES FILES! MAKE BACKUP! rdfind -deleteduplicates true ./search/in/this/folder
creditz: https://www.tecmint.com/find-and-delete-duplicate-files-in-linux/
duff
website: http://duff.dreda.org/
su - root; apt-get update; apt-get install duff; # install duff
duff examples:
Normal mode
Shows normal output, with a header before each cluster of duplicate files, in this case using
- recursive search (
-r) in .folder /comics
duff -r comics
2 files in cluster 1 (43935 bytes, digest ea1a856854c166ebfc95ff96735ae3d03dd551a2)
comics/Nemi/n102.png
comics/Nemi/n58.png
3 files in cluster 2 (32846 bytes, digest 00c819053a711a2f216a94f2a11a202e5bc604aa)
comics/Nemi/n386.png
comics/Nemi/n491.png
comics/Nemi/n512.png
2 files in cluster 3 (26596 bytes, digest b26a8fd15102adbb697cfc6d92ae57893afe1393)
comics/Nemi/n389.png
comics/Nemi/n465.png
2 files in cluster 4 (30332 bytes, digest 11ff80677c85005a5ff3e12199c010bfe3dc2608)
comics/Nemi/n380.png
comics/Nemi/n451.pngThe header can be customized (with the -f flag) for example outputing only the number of files that follow:
duff -r -f '%n' comics
2
comics/Nemi/n102.png
comics/Nemi/n58.png
3
comics/Nemi/n386.png
comics/Nemi/n491.png
comics/Nemi/n512.png
2
comics/Nemi/n389.png
comics/Nemi/n465.png
2
comics/Nemi/n380.png
comics/Nemi/n451.pngExcess mode
Duff can report all but one file from each cluster of duplicates (with the -e flag).
This can be used in combination with for examplerm to remove duplicates, but should only be done if you don’t care which duplicates are removed.
duff -re comics
comics/Nemi/n58.png
comics/Nemi/n491.png
comics/Nemi/n512.png
comics/Nemi/n465.png
comics/Nemi/n451.png
czkawka
https://github.com/qarmin/czkawka
czkawka it is the rust rewritten successor to fslint (fslint is no longer in the default Debian repo, for whatever reason)
what is neat about czkawka:
- it searches a directory for duplicate files and lists the biggest files first
- be-aware:
- the terminal version is sufficient (imho)
- Debian 11 (yet): was unable to install the gui
- plz prepare for a lengthy install that involves downloading a lot of software and compiling it
- the terminal version is sufficient (imho)
install:
# as default user curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh # check rust is installed rustc --version rustc 1.64.0 (a55dd71d5 2022-09-19) # warning! THIS WILL DOWNLOAD AND COMPILE A LOT! cargo install czkawka_cli # run it czkawka_cli dup --directories /where/to/search/for/duplicates | less # if the gui was required # become root su - root apt update apt install software-properties-common ffmpeg apt install libgdk-pixbuf-2.0-dev libghc-pango-dev libgraphene-1.0-dev librust-pango-sys-dev libglib2.0-dev cairo-dev libcairo2-dev librust-pango-sys-dev # Ctrl+D (logoff root) cargo install cairo-dev # can try to install gui, but won't work cargo install czkawka_gui
https://lib.rs/crates/czkawka_cli
help & more examples:
czkawka_cli --help czkawka 6.0.0 USAGE: czkawka_cli[SCFLAGS] [SCOPTIONS] OPTIONS: -h, --help Print help -V, --version Print version SUBCOMMANDS: dup Finds duplicate files empty-folders Finds empty folders big Finds big files empty-files Finds empty files temp Finds temporary files image Finds similar images music Finds same music by tags symlinks Finds invalid symlinks broken Finds broken files video Finds similar video files ext Finds files with invalid extensions tester Small utility to test supported speed of help Print this message or the help of the given subcommand(s) try "czkawka_cli -h" to get more info about a specific tool EXAMPLES: czkawka dup -d /home/rafal -e /home/rafal/Obrazy -m 25 -x 7z rar IMAGE -s hash -f results.txt -D aeo czkawka empty-folders -d /home/rafal/rr /home/gateway -f results.txt czkawka big -d /home/rafal/ /home/piszczal -e /home/rafal/Roman -n 25 -x VIDEO -f results.txt czkawka empty-files -d /home/rafal /home/szczekacz -e /home/rafal/Pulpit -R -f results.txt czkawka temp -d /home/rafal/ -E */.git */tmp* *Pulpit -f results.txt -D czkawka image -d /home/rafal -e /home/rafal/Pulpit -f results.txt czkawka music -d /home/rafal -e /home/rafal/Pulpit -z "artist,year, ARTISTALBUM, ALBUM___tiTlE" -f results.txt czkawka symlinks -d /home/kicikici/ /home/szczek -e /home/kicikici/jestempsem -x jpg -f results.txt czkawka broken -d /home/mikrut/ -e /home/mikrut/trakt -f results.txt czkawka extnp -d /home/mikrut/ -e /home/mikrut/trakt -f results.txt
recovery of deleted files?
if the original data is deleted, the softlink becomes “invalid” (does not point to anything anymore) and the data is gone (under ext3 undelete can be done wth ease, recovery data from ext4 is much harder and often only the data can be (completely or partially) be recovered but NOT the filename, which can leave the user with a massive mess of data to be (manually?) sorted.
Uusually there should be backups of data on other disks, so it would actually be cool to tell extundelete or photorec: “check it out, the filenames might be lost, but the data is still (at least partially) there. please look at this backup disk and try to compare if an (partly) identical file is in the backup, and reconstruct (undelete) the file under ./where/the/accident/happened accordingly
liked this article?
- only together we can create a truly free world
- plz support dwaves to keep it up & running!
- (yes the info on the internet is (mostly) free but beer is still not free (still have to work on that))
- really really hate advertisement
- contribute: whenever a solution was found, blog about it for others to find!
- talk about, recommend & link to this blog and articles
- thanks to all who contribute!
