wget way:
wget --no-check-certificate --limit-rate=5k --random-wait --recursive --no-clobber --page-requisites --html-extension --convert-links https://domain.com # remove "--random-wait" and rate "--limit-rate" if it's the user's website and bandwidth is no problem vim /scripts/download_website.sh; # create new file and fill with this content #!/bin/bash wget --no-check-certificate --limit-rate=5k --random-wait --recursive --no-clobber --page-requisites --html-extension --convert-links $1 chmod u+x /scripts/download_website.sh; # mark script executable mkdir /offline_websites_workspace; # create new dir where to offline the website cd /offline_websites_workspace; /scripts/download_website.sh "https://domain.com"; # recursively download domain.com
options explained:
- –mirror
- Turn on options suitable for mirroring.
- This option turns on recursion and time-stamping, sets infinite recursion depth and keeps FTP directory listings.
- It is currently equivalent to -r -N -l inf –no-remove-listing.
- –no-check-certificate (basically: enable https)
- Don’t check the server certificate against the available certificate authorities. Also don’t require the URL host name to match the common name presented by the certificate.
- –limit-rate=5k
- Limit the download speed to 5KBytes per second.
- –random-wait
- Some web sites may perform log analysis to identify retrieval programs such as Wget by looking for statistically significant similarities in the time between requests. This
- option causes the time between requests to vary between 0.5 and 1.5 * wait seconds, where wait was specified using the –wait option, in order to mask Wget’s presence from such analysis.
- A 2001 article in a publication devoted to development on a popular consumer platform provided code to perform this analysis on the fly. Its author suggested blocking at the class C address level to ensure automated retrieval programs were blocked despite changing DHCP-supplied addresses.
- The –random-wait option was inspired by this ill-advised recommendation to block many unrelated users from a web site due to the actions of one.
- –recursive
- download the entire Web site.
–domains website.org- don’t follow links outside website.org.
–no-parent- don’t follow links outside the directory tutorials/html/.
- –page-requisites
- get all the elements that compose the page (images, CSS and so on).
- –html-extension
- save files with the .html extension.
- –convert-links
- convert links so that they work locally, off-line (./relative/paths/)
- After the download is complete, convert the links in the document to make them suitable for local viewing.
- This affects not only the visible hyperlinks, but any part of the document that links to external content, such as embedded images, links to style sheets, hyperlinks to non-HTML content, etc.
- Each link will be changed in one of the two ways:
- The links to files that have been downloaded by Wget will be changed to refer to the file they point to as a relative link.
–restrict-file-names=windows- modify filenames so that they will work in Windows as well, fuck windows one does not need it.
- –no-clobber
- easy resume of when if connection breaks down: don’t overwrite any existing files (used in case the download is interrupted and resumed)
creditz: http://www.linuxjournal.com/content/downloading-entire-web-site-wget
manpage: wget.man.txt
WebHTTrack
httrack is a dedicated “download the entire website tool” that is written solely for this purpose
warning: some websites have brute force attack detectionand prevention in place (anti DDoS) and might block the copy process half way
setup:
hostnamectl; # tested on Static hostname: DebianLaptop Operating System: Debian GNU/Linux 9 (stretch) Kernel: Linux 4.9.0-13-amd64 Architecture: x86-64 su - root; apt update; apt install httrack webhttrack; Ctrl+D # logoff root # start local webserver:8080 webhttrack
start browser and go to localhost:8080
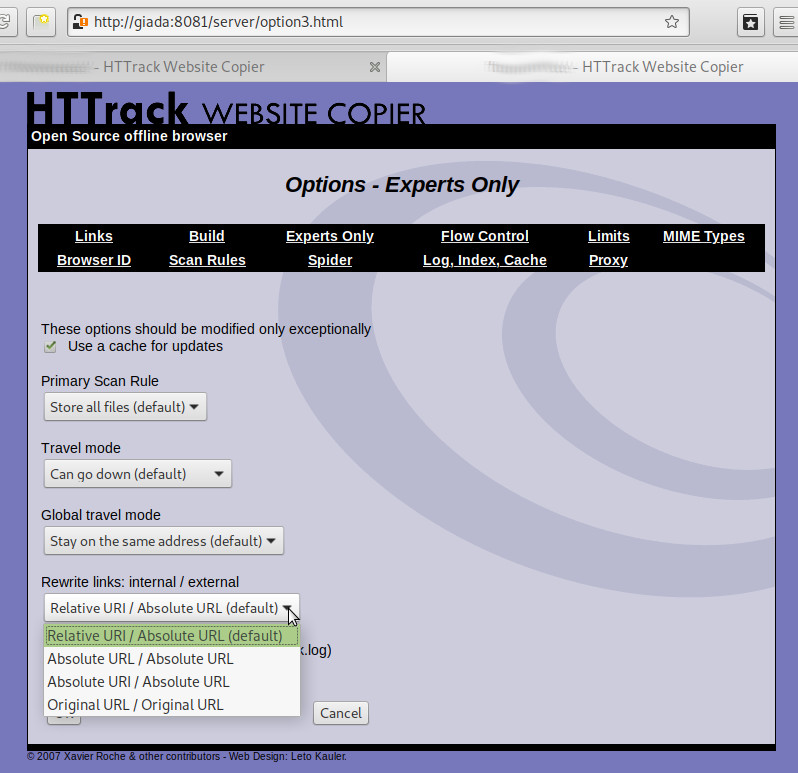
problem:
there seems to be no option for webHTTrack to convert absolute (https://domain.com/image/file.jpg) into relative (./image/file.jpg) paths?
this kind of sucks (wget can do that!)
https://www.linux-magazine.com/Online/Features/WebHTTrack-Website-Copier
liked this article?
- only together we can create a truly free world
- plz support dwaves to keep it up & running!
- (yes the info on the internet is (mostly) free but beer is still not free (still have to work on that))
- really really hate advertisement
- contribute: whenever a solution was found, blog about it for others to find!
- talk about, recommend & link to this blog and articles
- thanks to all who contribute!
