![]()
ZFS is probably THE most controversial filesytem in the known universe:
“FOSS means that effort is shared across organizations and lowers maintenance costs significantly” (src: comment by JohnFOSS on itsfoss.com)
“Mathematicians have a term for this. When you rearrange the terms of a series so that they cancel out, it’s called telescoping — by analogy with a collapsable hand-held telescope.
In a nutshell, that’s what ZFS does: it telescopes the storage stack.
That’s what allows us to have:
- a filesystem
- volume manager
- single- and double-parity RAID
- compression
- snapshots
- clones
- and a ton of other useful stuff in just 80,000 lines of code.”
- The ZFS architecture eliminates an entire layer of translation — and along with it, an entire class of metadata (volume LBAs).
- It also eliminates the need for hardware RAID controllers.
- (src: https://web.archive.org/web/20180510210331/https://blogs.oracle.com/bonwick/rampant-layering-violation)
“The whole purpose behind ZFS was to provide a next-gen filesystem for UNIX and UNIX-like operating systems.” (src: comment by JohnK3 on itsfoss.com)
“The performance is good, the reliability and protection of data is unparalleled, and the flexibility is great, allowing you to configure pools and their caches as you see fit. The fact that it is independent of RAID hardware is another bonus, because you can rescue pools on any system, if a server goes down. No looking around for a compatible RAID controller or storage device.”
“after what they did to all of SUN’s open source projects after acquiring them. Oracle is best considered an evil corporation, and anti-open source.”
“it is sad – however – that licensing issues often get in the way of the best solutions being used” (src: comment by mattlach on itsfoss.com)
“Zfs is greatly needed in Linux by anyone having to deal with very large amounts of data. This need is growing larger and larger every year that passes.” (src: comment by Tman7 on itsfoss.com)
“I need ZFS, because In the country were I live, we have 2-12 power-fails/week. I had many music files (ext4) corrupted during the last 10 years.” (src: comment by Bert Nijhof on itsfoss.com)
“some functionalities in ZFS does not have parallels in other filesystems. It’s not only about performance but also stability and recovery flexibility that drives most to choose ZFS.” (src: comment by Rubens on itsfoss.com)
“Some BtrFS features outperform ZFS, to the point where I would not consider wasting my time installing ZFS on anything. I love what BtrFS is doing for me, and I won’t downgrade to ext4 or any other fs. So at this point BtrFS is the only fs for me.” (src: comment by Russell W Behne on itsfoss.com)
“Btrfs Storage Technology: The copy-on-write (COW) file system, natively supported by the Linux kernel, implements features such as snapshots, built-in RAID, and self-healing via checksumming for data and metadata. It allows taking subvolume snapshots and supports offline storage migration while keeping snapshots. For users of enterprise storage systems, Btrfs provides file system integrity after unexpected power loss, helps prevent bitrot, and is designed for high-capacity and high-performance storage servers.” (src: storagereview.com)
BTRFS is GPL 3.0 licenced btw.
bachelor projects are written about btrfs vs zfs (2015)
warning!
it will have to recompile for every kernel update!
so… what does Mr A. say?: will ZFS ever be GPL 2.0 or 3.0? (better 2.0)
so…
ext4 is good for notebooks & desktops & workstations (that do regular backups on a separate, external, then disconnected medium)
is zfs “better” on/for servers? (this user says: even on single disk systems, zfs is “better” as it prevents bit-rot-file-corruption)
with server-hardware one means:
- computers with massive computational resources (CPUs, RAM & disks)
- at least 2 disks for RAID1 (mirroring = safety)
- or better: 4 disks for RAID10 (striping + mirroring = speed + safety)
- zfs wants direct access to disks without any hardware raid controller or caches in between, so it is “fine” with simple SATA onboard connections or hba cards that do nothing but provide SATA / SAS / NVMe ports or hardware raid controllers that behave like hba cards (JBOD, some need firmware flashed, some need to be jumpered)
- fun fact: this is not the default for servers. servers (usually) come with LSI (or other vendor) hardware raid cards, that might be possible to JBOD jumper or flash) but that would mean: zfs is only good for servers WITHOUT hardware raid cards X-D (and those are (currently still) rare X-D)
- but they would be “perfect” fit for a consumer-hardware PC (having only SATA ports) used as server (many companies not only Google but also Proxmox and even Hetzner test out that way of operation, but it might not be the perfect fit for every admin, that rather spends some bucks extra and wants to provide companies with the most reliable hardware possible (redundant power supplies etc.)
- maybe that is also a cluster vs mainframe “thinking”
- so in a cluster, if some nodes fail, it does not matter, as other nodes take over and are replaced fast (but some server has to store the central database, that is not allowed to fail X-D)
- in a non-cluster environment, things might be very different
- fun fact: this is not the default for servers. servers (usually) come with LSI (or other vendor) hardware raid cards, that might be possible to JBOD jumper or flash) but that would mean: zfs is only good for servers WITHOUT hardware raid cards X-D (and those are (currently still) rare X-D)
- “to EEC or not to EEC the RAM”, that is the question?:
- zfs also runs on machines without EEC but:
- in semi-professional purposes non-EEC might be okay
- for companies with critical data maximum error correction EEC is a must (as magnetic fields / sunflares could potentially flip some bits in RAM, then write the faulty data back to disk, ZFS can not correct that)
- “authors of a 2010 study that examined the ability of file systems to detect and prevent data corruption, with particular focus on ZFS, observed that ZFS itself is effective in detecting and correcting data errors on storage devices, but that it assumes data in RAM is “safe”, and not prone to error”
- “One of the main architects of ZFS, Matt Ahrens, explains there is an option to enable checksumming of data in memory by using the ZFS_DEBUG_MODIFY flag (zfs_flags=0x10) which addresses these concerns.[73]” (wiki)
- zfs also runs on machines without EEC but:
zfs: snapshots!
zfs has awesome features such as:
- snapshots:
- allows to recover from “ooops just deleted everything” errors and ransomeware attacks (unless the ransomeware is zfs “aware” and deletes all snapshots)
- extundelete does not work well for ext4
- testdisk -> photorec can recover data from ext4 but not the /directory/structure/filenames!!!
- ext4 can do snapshots as well with lvm2, but those lvm2 snapshots are more temporary “buffers” that can run out of changes-written-space and are then disgarded, so not “real” and “permanent” snapshots that can be restored or copied to a different system without time-limitation.
- zfs comes with data compression to safe disk space (won’t work well for “binary” data such as jpg or mp4 but anything text)
many more featuers:
- Protection against data corruption. Integrity checking for both data and metadata.
- Continuous integrity verification and automatic “self-healing” repair
- Data redundancy with mirroring, RAID-Z1/2/3 [and DRAID]
- Support for high storage capacities — up to 256 trillion yobibytes (2^128 bytes)
- Space-saving with transparent compression using LZ4, GZIP or ZSTD
- Hardware-accelerated native encryption
- Efficient storage with snapshots and copy-on-write clones
- Efficient local or remote replication — send only changed blocks with ZFS send and receive
(src)
how much space do snapshots use?
look at WRITTEN, not at USED.
zfs list -t snapshot -r -o name,written,used,refer raid10pool/dataset1

https://papers.freebsd.org/2019/bsdcan/ahrens-how_zfs_snapshots_really_work/
performance?
so on a single-drive system, performance wise ext4 is what the user wants.
on multi-drive systems, the opposite might be true, zfs outperforming ext4.
it is a filesystem + a volumen manager! 🙂
“is not necessary nor recommended to partition the drives before creating the zfs filesystem” (src, src of src)
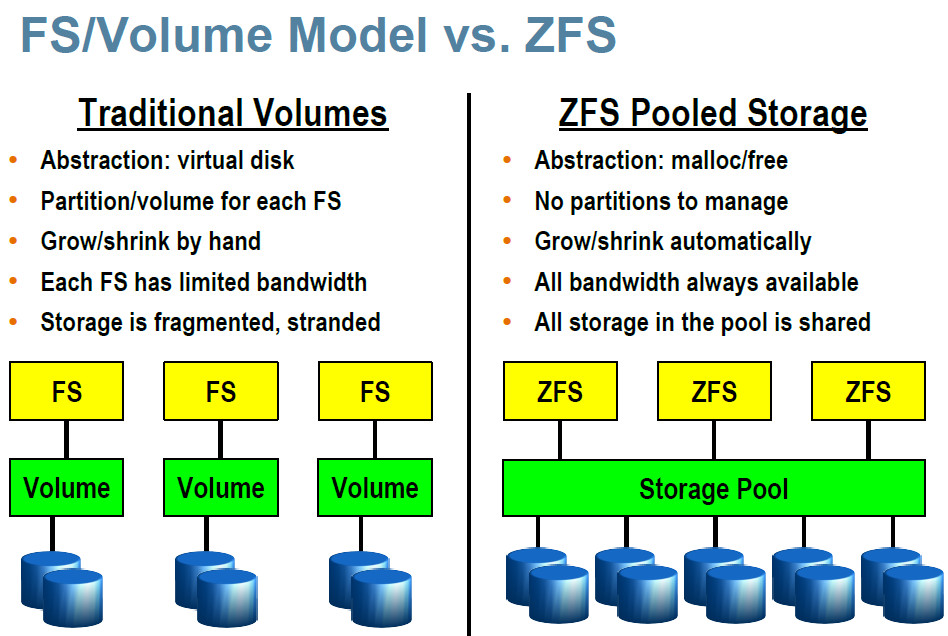
zfs “raid” levels:
- “raid5 or raidz distributes parity along with the data
- can lose 1x physical drive before a raid failure.
- Because parity needs to be calculated raid 5 is slower then raid0, but raid 5 is much safer.
- RAID 5 requires at least 3x hard disks in which one(1) full disk of space is used for parity.
- raid6 or raidz2 distributes parity along with the data
- can lose 2x physical drives instead of just one like raid 5.
- Because more parity needs to be calculated raid 6 is slower then raid5, but raid6 is safer.
- raidz2 requires at least 4x disks and will use two(2) disks of space for parity.
- raid7 or raidz3 distributes parity just like raid 5 and 6
- but raid7 can lose 3x physical drives.
- Since triple parity needs to be calculated raid 7 is slower then raid5 and raid 6, but raid 7 is the safest of the three.
- raidz3 requires at least 4x, but should be used with no less then 5x disks, of which 3x disks of space are used for parity.
- raid10 or raid1+0 is mirroring and striping of data.
- The simplest raid10 array has 4x disks and consists of two pairs of mirrors.
- Disk 1 and 2 are mirrors and separately disk 3 and 4 are another mirror.
- Data is then striped (think raid0) across both mirrors.
- One can lose one drive in each mirror and the data is still safe.
- One can not lose both drives which make up one mirror, for example drives 1 and 2 can not be lost at the same time.
- Raid 10 ‘s advantage is reading data is fast.
- The disadvantages are the writes are slow (multiple mirrors) and capacity is low.”
ZFS supports SSD/NVMe caching + RAM caching:
more RAM is better than an dedicated SSD/NVMe cache, BUT zfs can do both! which is remarkable.
(the optimum probably being RAM + SSD/NVMe caching)
ubuntu uses Debian’s choice ext4 as default filesystem
- “our ZFS support with ZSys is still experimental.” https://ubuntu.com/blog/zfs-focus-on-ubuntu-20-04-lts-whats-new
- “Ubuntu did not “pick” ext4. Debian did.”
- “Mark Shuttleworth’s original vision was to create a not-quite-fork of Debian that could sign contracts, collect revenue, and hire engineers. A corollary to that vision of Debian-for-enterprise was that Ubuntu had to hew very close to stock Debian.”
- “It still does. That’s why Ubuntu uses Debian sources, apt, NetworkManager, systemd, …and ext4… among many other Debian-made decisions.”
- “The Ubuntu Foundations Team does have the authority to strike a different path, and on occasion it has done so. But for most issues the Ubuntu Foundations Team has agreed with the Debian consensus.”
- “Ubuntu and Debian do run happily on many different filesystems, and users can install Debian or Ubuntu on those filesystems fairly easily. Debian’s default, however, remains ext4.” (src)
ZFS licence problems/incompatibility with GPL 2.0 #wtf Oracle! again?
Linus: “And honestly, there is no way I can merge any of the ZFS efforts until I get an official letter from Oracle that is signed by their main legal counsel or preferably by Larry Ellison himself that says that yes, it’s ok to do so and treat the end result as GPL’d.” (itsfoss.com)
comment by vagrantprodigy: “Another sad example of Linus letting very limited exposure to something (and very out of date, and frankly, incorrect information about it’s licensing) impact the Linux world as a whole. There are no licensing issues, OPENZFS is maintained, and the performance and reliability is better than the alternatives.” (itsfoss.com)


it is Open Source, but not GPL licenced: for Linus, that’s a no go and quiet frankly, yes it is a problem.
“this article missed the fact that CDDL was DESIGNED to be incompatible with the GPL” (comment by S O on itsfoss.com)
it can also be called “bait”
In this respect, the article is a good caution to bear in mind, that the differences in licensing can have consequences, later in time.Good article to encourage linux users to also bear in mind, that using any programs that are not GNU Gen. Pub. License (GPL) 2.0 can later on have consequences for use having affect on a lot of people, big time.
That businesses (corportions have long life spans) want to dominate markets with their products, and competition is not wanted.
So, how do you eliminate or hinder the competition?
… Keep Linux free as well as free from legal downstream entanglements.”
(comment by Bruce Lockert on itsfoss.com)
Guess one is not alone with that thinking: “Linus has nailed the coffin of ZFS! It adds no value to open source and freedom. It rather restricts it. It is a waste of effort. Another attack at open source. Very clever disguised under an obscure license to trap the ordinary user in a payed environment in the future.” (comment by Tuxedo on itsfoss.com)
GNU Linux Debian warns during installation:

“Licenses of OpenZFS and Linux are incompatible”
- OpenZFS is licensed under the Common Development and Distribution License (CDDL), and the Linux kernel is licensed under the GNU General Public License Version 2 (GPL-2).
- While both are free open source licenses they are restrictive licenses.
- The combination of them causes problems because it prevents using pieces of code exclusively available under one license with pieces of code exclusively available under the other in the same binary.
- You are going to build OpenZFS using DKMS in such a way that they are not going to be built into one monolithic binary.
- Please be aware that distributing both of the binaries in the same media (disk images, virtual appliances, etc) may lead to infringing.
“You cannot change the license when forking (only the copyright owners can), and with the same license the legal concerns remain the same. So forking is not a solution.” (comment by MestreLion on itsfoss.com)
OpenZFS 2.0
“This effort is fast-forwarding delivery of advances like dataset encryption, major performance improvements, and compatibility with Linux ZFS pools.” (src: truenas.com)
tricky.
of course users can say “haha”  “accidentally deleted millions of files” “no backups” “now snapshots would be great”
“accidentally deleted millions of files” “no backups” “now snapshots would be great”
or come up with a smart file system, tha can do snapshots.
how to on GNU Linux Debian 11:
the idea is to:
- test it out in a vm
- create a raid1 like zfs raid
- create some test files
- snapshot
- delete test files
- restore
- then redo the test on “proper” server hardware and also run some benchmarks
how to install:
lsb_release -a; # tested on Distributor ID: Debian Description: Debian GNU/Linux 11 (bullseye) Release: 11 Codename: bullseye su - root # create new file to include backports repo echo "deb http://deb.debian.org/debian buster-backports main contrib" >> /etc/apt/sources.list.d/buster-backports.list echo "deb-src http://deb.debian.org/debian buster-backports main contrib" >> /etc/apt/sources.list.d/buster-backports.list # create another new file echo "Package: libnvpair1linux libnvpair3linux libuutil1linux libuutil3linux libzfs2linux libzfs4linux libzpool2linux libzpool4linux spl-dkms zfs-dkms zfs-test zfsutils-linux zfsutils-linux-dev zfs-zed" >> /etc/apt/preferences.d/90_zfs echo "Pin: release n=buster-backports" >> /etc/apt/preferences.d/90_zfs echo "Pin-Priority: 990" >> /etc/apt/preferences.d/90_zfs apt update apt install dpkg-dev linux-headers-$(uname -r) linux-image-amd64 apt install zfs-dkms zfsutils-linux # accept that the zfs licence sucks and reboot the system reboot # check if kernel modules are loaded lsmod|grep zfs zfs 4558848 6 zunicode 335872 1 zfs zzstd 573440 1 zfs zlua 184320 1 zfs zavl 16384 1 zfs icp 323584 1 zfs zcommon 102400 2 zfs,icp znvpair 106496 2 zfs,zcommon spl 118784 6 zfs,icp,zzstd,znvpair,zcommon,zavl # what disks are there? # optional but the user might find this alias usefull for overview alias loop_df='while true; do (clear; echo '\''=========== looped harddisk info '\''; datum; dmesg|tail -n20; echo '\''=========== where is what'\''; harddisks; echo '\''=========== harddisk usage'\''; df -Th;) ; sleep 1 ; done lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 128G 0 disk ├─sda1 8:1 0 100G 0 part / └─sda2 8:2 0 28G 0 part [SWAP] sdb 8:16 0 128G 0 disk <- those two shall be become a zfs raid1 sdc 8:32 0 128G 0 disk <-/ sr0 11:0 1 58.2M 0 rom # now the magic moment: # hint no need to make a partition table or partitions zpool create -f pool1 /dev/sdb /dev/sdc # congratz! :) now destroy the pool immediately again # because using drive letters instead of device-ids will mean trouble!!! zpool destroy -f pool1 # also need to wipe filesystem partition harddisk meta data wipefs -a /dev/sdb wipefs -a /dev/sdc # ZFS on Linux recommends device IDs for ZFS storage pools x < 10 devices # use Persistent block device naming#by-id and by-path to identify ls -lh /dev/disk/by-id/|grep sdb lrwxrwxrwx 1 root root 9 Jan 28 13:46 ata-VBOX_HARDDISK_VB11e808c8-0adfad57 -> ../../sdb ls -lh /dev/disk/by-id/|grep sdc lrwxrwxrwx 1 root root 9 Jan 28 13:46 ata-VBOX_HARDDISK_VB133d1052-670572f8 -> ../../sdc # raid1 (at least 2x disks required, 1x disk may fail) zpool create -f raid1pool mirror /dev/disk/by-id/ata-VBOX_HARDDISK_VB11e808c8-0adfad57 /dev/disk/by-id/ata-VBOX_HARDDISK_VB133d1052-670572f8 # raid10 (at least 4x disks required, 2x disks (one out of every mirror set) may fail) zpool create raid10pool mirror disk1 disk2 mirror disk3 disk4 # raid5 = raidz (at least 3x disks required, 1x disk may fail) zpool create -f raid5pool raidz disk1 disk2 disk3 # to extend raidz pool e.g. add disk4 zpool add -f raid5pool disk4 # raidz2 = raid6 (3x disks required, 2x disks may fail) zpool create -f raid6pool raidz2 disk1 disk2 disk3 # going for raid1 for now # want that famous data compression lz4 :) # what is being used right now? zfs get compression raid1pool # set that favmous lz4 as compression algorithm to be used # (performs way better than gzip!) zfs set compression=lz4 raid1pool # if access time of files is not needed, more performance when turned off zfs set atime=off raid10pool zfs list NAME USED AVAIL REFER MOUNTPOINT raid1pool 102K 123G 24K /raid1pool # ZFS datasets are like filesystem partitions zfs create raid1pool/dataset1 zfs create raid1pool/dataset2 zfs create raid1pool/dataset3 # to delete a partition zfs destroy pool1/dataset3 # as with raid1, half of the available space can be used (minus metadata) for storage zfs list NAME USED AVAIL REFER MOUNTPOINT raid1pool 213K 123G 24K /raid1pool raid1pool/dataset1 24K 123G 24K /raid1pool/dataset1 raid1pool/dataset2 24K 123G 24K /raid1pool/dataset2 # how to mount? # zfs automatically creates new directories /raid1pool/dataset1 and mounts there # per default under GNU Linux Debian mouting under /media/user # this makes the mount integrate well with the gui / easy access for the gui-user # modify mountpoint: zfs set mountpoint=/media/user/dataset1 raid1pool/dataset1 # give user ownership and thus write access chown -R user: /media/user/dataset1 # ready2use :)

# how to create a new mountpoint for a ZFS filesystem zfs create raid1pool/dataset1 -o mountpoint=/new/moint/point # checkout the storage setup loop_df =========== where is what NAME MAJ:MIN RM SIZE RO FSTYPE MOUNTPOINT UUID sda 8:0 0 128G 0 ├─sda1 8:1 0 100G 0 ext4 / a6abe7b9-250a-4ffa-84e1-cf48425d85fb └─sda2 8:2 0 28G 0 swap [SWAP] d0fda799-9f12-47cc-9bfe-468fd56cd2ee sdb 8:16 0 128G 0 ├─sdb1 8:17 0 128G 0 zfs_member 12433959490844008291 └─sdb9 8:25 0 8M 0 sdc 8:32 0 128G 0 ├─sdc1 8:33 0 128G 0 zfs_member 12433959490844008291 └─sdc9 8:41 0 8M 0 sr0 11:0 1 58.2M 0 iso9660 2020-09-04-07-49-40-62 =========== harddisk usage Filesystem Type Size Used Avail Use% Mounted on udev devtmpfs 464M 0 464M 0% /dev tmpfs tmpfs 98M 1.1M 97M 2% /run /dev/sda1 ext4 98G 5.5G 87G 6% / tmpfs tmpfs 489M 0 489M 0% /dev/shm tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs tmpfs 98M 96K 98M 1% /run/user/1000 raid1pool zfs 124G 128K 124G 1% /raid1pool raid1pool/dataset2 zfs 124G 128K 124G 1% /raid1pool/dataset2 raid1pool/dataset3 zfs 124G 128K 124G 1% /raid1pool/dataset3 raid1pool/dataset1 zfs 124G 128K 124G 1% /media/user/dataset1 # now let's snapshot some datasets # zfs does not complain when snapshotting a whole pool, but reverting those snapshots does not bring back the data (for some reason?) # take snapshot of "partition" dataset1 name it snapshot1 zfs snapshot raid1pool/dataset1@snapshot1 # add some data to /raid1pool/dataset1 touch /raid1pool/dataset1/1 touch /raid1pool/dataset1/2 touch /raid1pool/dataset1/3 # abort that after a few seconds with Ctrl+C time dd if=/dev/random of=/raid1pool/dataset1/random.file bs=1 # create another snapshot of that "partition" dataset1 zfs snapshot raid1pool/dataset1@snapshot2 # let's checkout the snapshots: list all snapshots of dataset1 zfs list -t snapshot -r raid1pool/dataset1 NAME USED AVAIL REFER MOUNTPOINT raid1pool/dataset1@snapshot4 15K - 48K zfs list -t all -o name,written,used,refer raid1pool/dataset1 NAME WRITTEN USED REFER raid1pool/dataset1 0 186M 186M # not a lot of info try again zfs list -t snapshot -r -o name,written,used,refer raid10pool/dataset1 NAME WRITTEN USED REFER raid10pool/dataset1@snapshot-2022-02-01 96K 64K 96K raid10pool/dataset1@snapshot-2022-02-06 3.13T 83.0G 3.13T raid10pool/dataset1@snapshot-2022-02-06_12_26 45.6G 0B 3.10T # let's delete everything rm -rf /raid1pool/dataset1/* # confirm that the files are gone ls -lah /raid1pool/dataset1/ total 4.5K drwxr-xr-x 2 user user 2 Jan 30 19:04 . drwxr-xr-x 3 root root 4.0K Jan 30 18:58 # let's restore snapshot2 zfs rollback raid1pool/dataset1@snapshot2 # confirm the files are back :) HURRAY! NO MORE DATALOSS EVER AGAIN? ls -lah /raid1pool/dataset1/ total 187M drwxr-xr-x 3 user user 9 2022-01-30 . drwxr-xr-x 3 root root 4.0K 2022-01-30 .. -rw-r--r-- 1 root root 186M 2022-01-30 random.file
Caution: If you are in a poorly configured environment (e.g. certain VM or container consoles), when apt attempts to pop up a message on first install, it may fail to notice a real console is unavailable, and instead appear to hang indefinitely. To circumvent this, you can prefix the apt install commands with DEBIAN_FRONTEND=noninteractive, like this:
DEBIAN_FRONTEND=noninteractive apt install zfs-dkms zfsutils-linux
creditz: https://openzfs.github.io/openzfs-docs/Getting%20Started/Debian/index.html
regular weekly (automatic/automated) snapshots:
lsb_release -a; # tested on Description: Debian GNU/Linux 11 (bullseye) su - root; # become root # create a script like this vim /scripts/zfs/snapshot.sh #!/bin/bash # the next line seems superfluous, but placing this directly behind zfs command will (for some reason) not work SNAPSHOT_NAME=$(date '+%Y-%m-%d_%H_%M') echo "=== snapshotting zfs dataset1 ===" # logging exact date and time when zfs snapshot was run echo "taking zfs snapshot raid10pool/dataset1@snapshot-$SNAPSHOT_NAME at $(date '+%Y-%m-%d_%H:%M:%S')" >> /var/log/zfs.log zfs snapshot raid10pool/dataset1@snapshot-$SNAPSHOT_NAME # mark it runnable chmod +x /scripts/zfs/*.sh # put this in crontab crontab -e 5 8 * * 0 /scripts/zfs/snapshot.sh; # every sunday at 8:05 # test if it worked zfs list -t snapshot -r -o name,written,used,refer raid10pool/dataset1 NAME WRITTEN USED REFER raid10pool/dataset1@snapshot-2022-02-01 96K 64K 96K raid10pool/dataset1@snapshot-2022-02-06 3.13T 83.0G 3.13T raid10pool/dataset1@snapshot-2022-02-06_12_26 45.6G 0B 3.10T # it worked :)
note:
with ext4 it was recommended to put GNU Linux /root and /swap on a dedicated SSD/NVMe (that then regularly backs up to the larger raid10)
but than the user would miss out on the zfs awesome restore snapshot features, which would mean:
- no more fear of updates
- take snapshot before update
- do system update (moving between major versions of Debian 9 -> 10 can be problematic, sometimes it works, sometimes it will not)
- test the system according to list of use cases (“this used to work, this too”)
- if update breaks stuff -> boot from a usb stick -> roll back snapshot (YET TO BE TESTED!)
very basic harddisk benchmark:
the hardware:
- Supermicro X9SCI/X9SCA + Intel Xeon E3-1200 v2/Ivy + 4 x 4001GB Hitachi HUS72404
- 1) dd: writing & reading /dev/zero
time dd if=/dev/zero of=./testfile bs=3G count=1 oflag=direct time dd if=./testfile bs=3GB count=1 of=/dev/null
- “raid10pool” (zpool create raid10pool mirror disk1 disk2 mirror disk3 disk4) compression: off
- sequential writing: 3GB of zeros: 230 MB/s, sequential reading 6GB of zeros: 3.6 GB/s, completed in real 11.460s
- “raid10pool” (zpool create raid10pool mirror disk1 disk2 mirror disk3 disk4) compression: lz4
- sequential writing: 3GB of zeros: 935 MB/s, sequential reading 6GB of zeros: 4.6 GB/s, completed in real 2.793s
as can be seen: zeros compress really really well 🙂 (so it is way faster with writing & reading zeros with compression lz4 enabled (yes lz4 is also a very fast compression algorithm, there was some CPU usage going up shortly (few seconds) to 40%))
phoronix-test-suite by openbenchmarking.org
Warning! this test will install a lot of stuff (including php-cli) and possibly upload a lot of system details to openbenchmarking.org
tried to use the exact settings of this zfs vs ext4 benchmark:
write test:
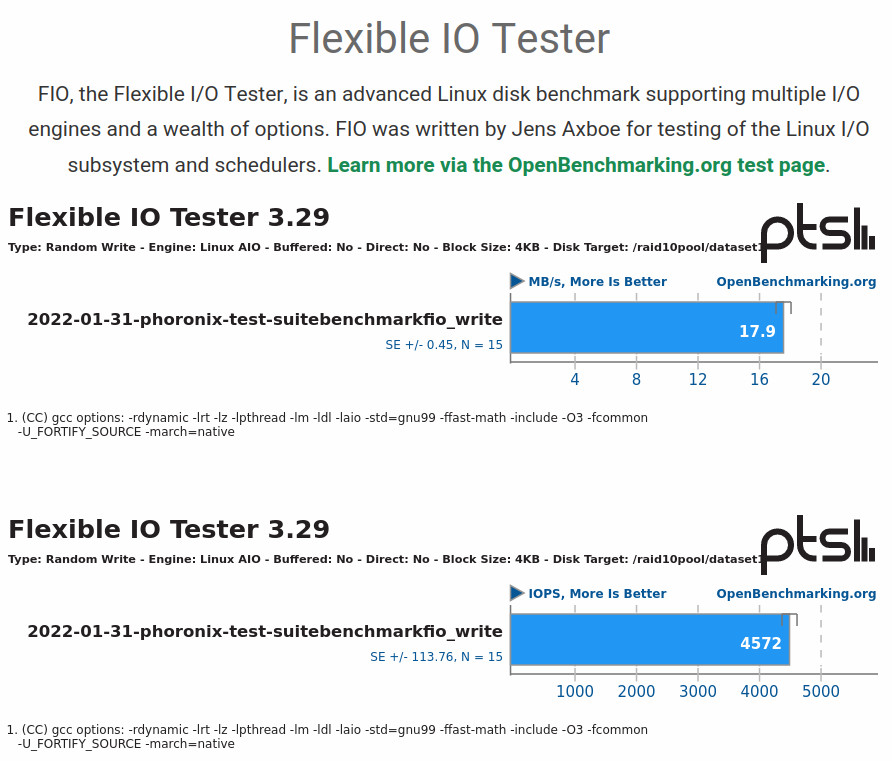
read test:

soooo…
wow! if that was correct, it would be really really bad 17.9MBytes/sec of write performance can’t possibly be right.
this can be simply proofed wrong by:
cd /raid10pool/dataset1 # generating 1GB_of_random_data head -c 1024m /dev/zero | openssl enc -aes-128-cbc -pass pass:"$(head -c 20 /dev/urandom | base64)" > 1GB_of_random_data # then taking the time copying that from the zfs dataset1 to zfs dataset1 time cp -rv 1GB_of_random_data 1GB_of_random_data1 real 0m0.682s; # first time real 0m0.684s; # second time real 0m1.025s; # third time # so this zfs setup can DEFINATELY write stuff FASTER than 17.9MBytes/sec # (yes it really is random data) head 1GB_of_random_data1 Salted__�a��oz��&HZL��`*��!�U�7R"��+�n�[G��(6[s�}� �~*փD�ʻ������OK?}KҊ��alnp� ��f)f`�u�Ƌ��������Y�z�4�1)���ɡgA�C���g]W� ��@2��I�D>})L?�ԅ�8Ni5���87����-�y1颰���9�|Vn���5t J����6.(�E���s���n��O ���\[�T8`��Q[�{�w0��Ҝ��/�]��W=�Q�h�,}�{�H������;m��-�lv�~����{�Ui��(�mv���M ����T�<��M�aY����W'̸8p��D�
how to setup the test suite:
# requirements apt install zlib1g-dev # download wget https://github.com/phoronix-test-suite/phoronix-test-suite/releases/download/v10.8.1/phoronix-test-suite_10.8.1_all.deb # install dpkg -i phoronix-test-suite_10.8.1_all.deb # run phoronix-test-suite benchmark fio # it will ask a lot of questions Type: Random Read - Engine: Linux AIO - Buffered: No - Direct: No - Block Size: 4KB - Disk Target: /raid10pool/dataset1 # and leave a 1.0G fiofile that has to be cleaned up manually # how to uninstall apt --purge remove phoronix-test-suite; apt autoremove;
creditz: Links:
but be aware of the pitfalls!
# get blocksize of sda
cat /sys/block/sda/queue/physical_block_size
4096
“Ashift tells ZFS what the underlying physical block size your disks use is. It’s in bits, so ashift=9 means 512B sectors (used by all ancient drives), ashift=12 means 4K sectors (used by most modern hard drives), and ashift=13 means 8K sectors (used by some modern SSDs).
If you get this wrong, you want to get it wrong high. Too low an ashift value will cripple your performance. Too high an ashift value won’t have much impact on almost any normal workload.
Ashift is per vdev, and immutable once set. This means you should manually set it at pool creation, and any time you add a vdev to an existing pool, and should never get it wrong because if you do, it will screw up your entire pool and cannot be fixed.” (src: jrs-s.net)
no creditz4: https://linuxhint.com/install-zfs-debian/ for misguiding users to use DRIVE LETTERS for zfs pool creation that will get users in trouble!
liked this article?
- only together we can create a truly free world
- plz support dwaves to keep it up & running!
- (yes the info on the internet is (mostly) free but beer is still not free (still have to work on that))
- really really hate advertisement
- contribute: whenever a solution was found, blog about it for others to find!
- talk about, recommend & link to this blog and articles
- thanks to all who contribute!

“There is always a thing called “in roads”, where it can also be called “bait”.
“The article says a lot in this respect.
“That Microsoft founder Bill Gate comment a long time ago was that “nothing should be for free.”
That too rings out loud, especially in today’s American/European/World of “corporate business practices” where they want what they consider to be their share of things created by others.
Just to be able to take, with not doing any of the real work.
That the basis of the GNU Gnu Pub. License (GPL) 2.0 basically says here it is, free, and the Com. Dev. & Dist.
License (CDDL) 1.0 says use it for free, find our bugs, but we still have options on its use, later on downstream.
..